MySQL 事务、触发器、范式
事务、触发器、范式
一、事务
1.1 事务的概念
1.1.1 什么是事务:
如果一个业务操作中多次访问了数据库,必须保证每条SQL语句都执行成功。如果其中有一条执行失败,所有已经执行过的代码必须回滚。回到没有执行前的状态。称为事务。简单来说就是要么所有的SQL语句全部执行成功,要么全部失败。
1.1.2 事务的四大特性
| 事务特性 | 含义 |
|---|---|
| 原子性(Atomicity) | 事务是工作的最小单元,整个工作单元要么全部执行成功,要么全部执行失败 |
| 一致性(Consistency) | 事务执行前与执行后,数据库中数据应该保持相同的状态。如:转账前总金额与转账后总金额相同。 |
| 隔离性(Isolation) | 事务与事务之间不能互相影响,必须保持隔离性。 |
| 持久性(Durability) | 如果事务执行成功,对数据库的操作是持久的。 |
1.2 事务的应用场景说明
- 转账的操作
1 | drop database if exists db05; |
- 转账需求:
模拟a给b转500元钱,一个转账的业务操作最少要执行下面的2条语句:
a账号-500
b账号+500
1 | -- 转账操作 |
假设当a账号上-500元,服务器崩溃了。b的账号并没有+500元,数据就出现问题了。我们需要保证其中一条SQL语句出现问题,整个转账就算失败。只有两条SQL都成功了转账才算成功。这个时候就需要用到事务。
1.3 手动提交事务
MYSQL中可以有两种方式进行事务的操作:
- 手动提交事务
- 自动提交事务,默认是自动提交事务。
1.3.1 手动提交事务的SQL语句
| 功能 | SQL语句 |
|---|---|
| 开启事务 | start transaction/begin |
| 提交事务 | commit |
| 回滚事务 | rollback |
1.3.2 手动提交事务使用过程:
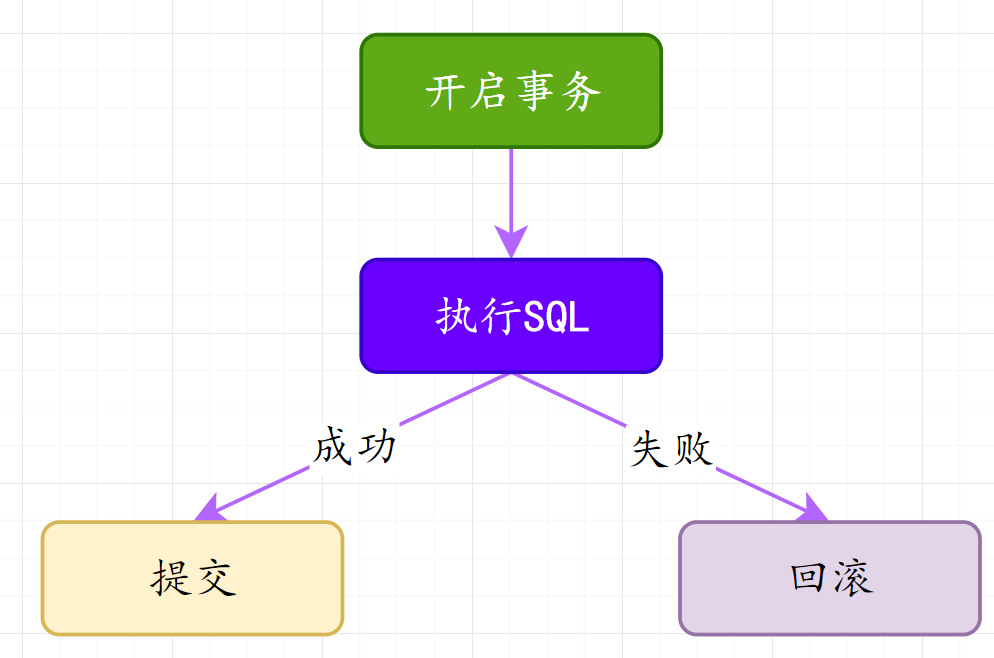
1.3.3 案例演示1:事务提交
模拟a给b转500元钱(成功) 目前数据库数据如下:
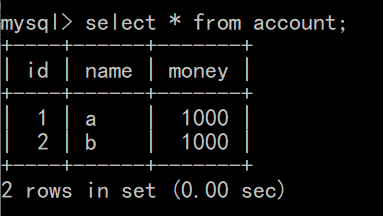
- 使用DOS控制台进入MySQL
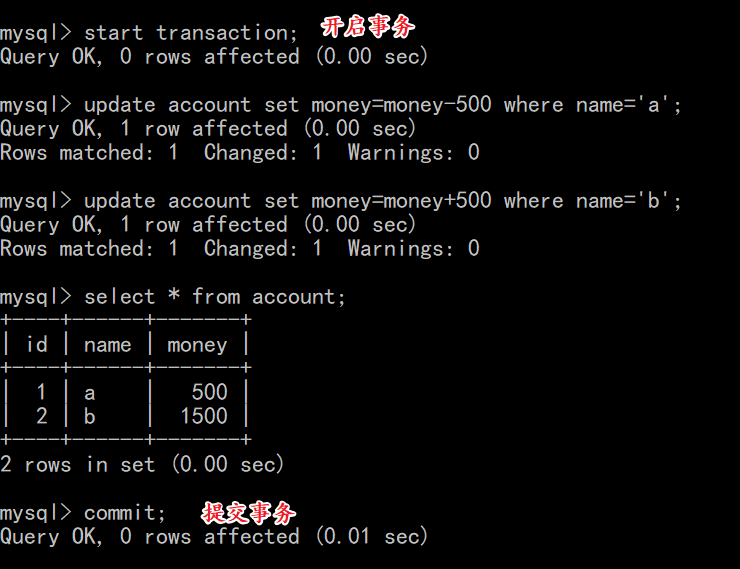
- 执行以下SQL语句: 1.开启事务, 2.xiaodong账号-500, 3.xiaobiao账号+500
- 使用Navicat查看数据库:发现数据并没有改变
- 在控制台执行commit提交任务:
- 使用Navicat查看数据库:发现数据改变
1 | -- 开启事务 |
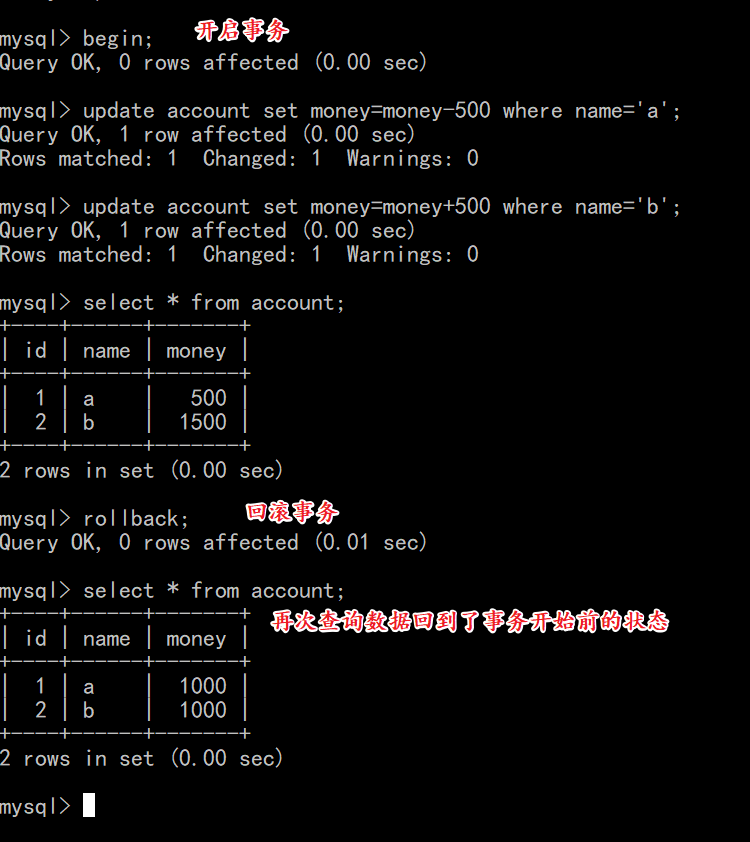
1.3.4 案例演示2:事务回滚
首先还原数据:
模拟a给b转500元钱(失败)
- 在控制台执行以下SQL语句:1.开启事务, 2.a账号-500
- 使用Navicat查看数据库:发现数据并没有改变
- 在控制台执行rollback回滚事务:
- 使用Navicat查看数据库:发现数据没有改变
1 | -- 开启事务 |
- 结论:
- 如果事务中SQL语句没有问题,那就commit提交事务,会对数据库数据的数据进行改变。
- 如果事务中SQL语句有问题,那就rollback回滚事务,会回退到开启事务时的状态。
1.4 自动提交事务
MySQL默认每一条DML(增删改)语句都是一个单独的事务,每条语句都会自动开启一个事务,执行完毕自动提交事务,MySQL默认开始自动提交事务
1.4.1 案例演示3:自动提交事务
- 将金额重置为1000
- 更新其中某一个账户
- 使用Navicat查看数据库:发现数据已经改变
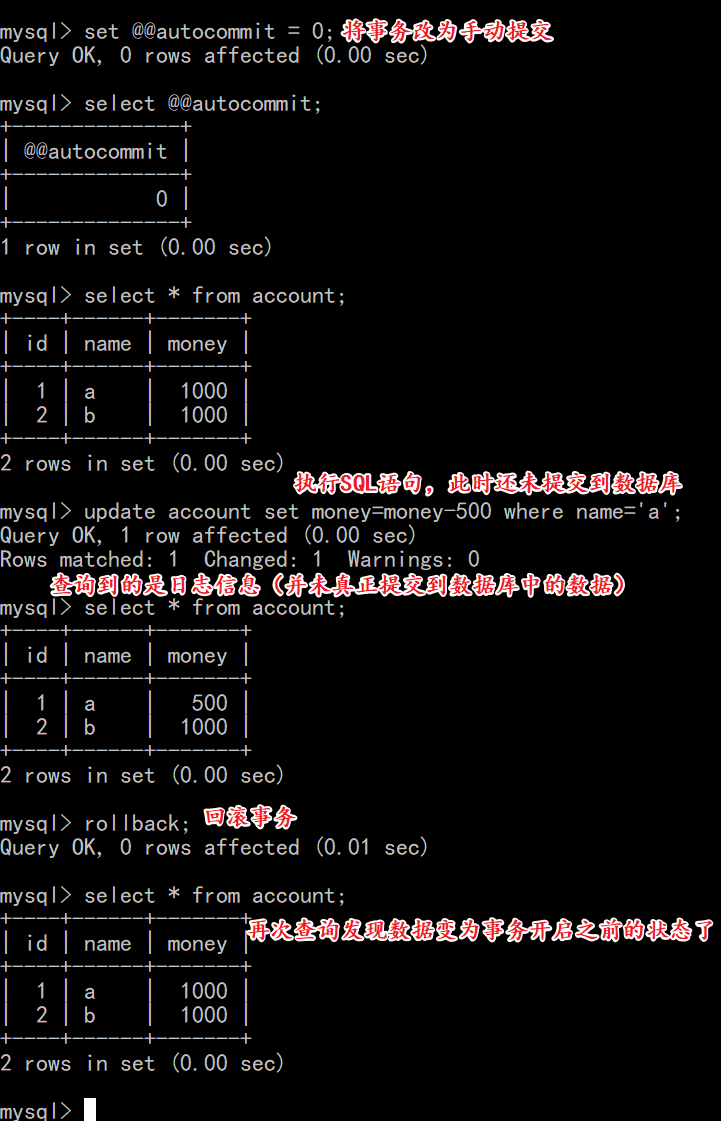
1.4.2 取消自动提交
- 查看MySQL是否开启自动提交事务
1 | select @@autocommit; |
如果是1:表示自动提交,默认值
如果是0:表示关闭了自动提交
- 取消自动提交事务
1 | set @@autocommit = 0; |
再次执行SQL语句:
1 | select * from account; |
- 执行更新语句,使用Navicat查看数据库,发现数据并没有改变,在控制台执行commit提交任务
1.5 事务原理
事务开启之后, 所有的操作都会临时保存到事务日志中,事务日志只有在得到commit命令才会同步到数据表中,其他任何情况都会清空事务日志(rollback,断开连接)
1.5.1 原理图:
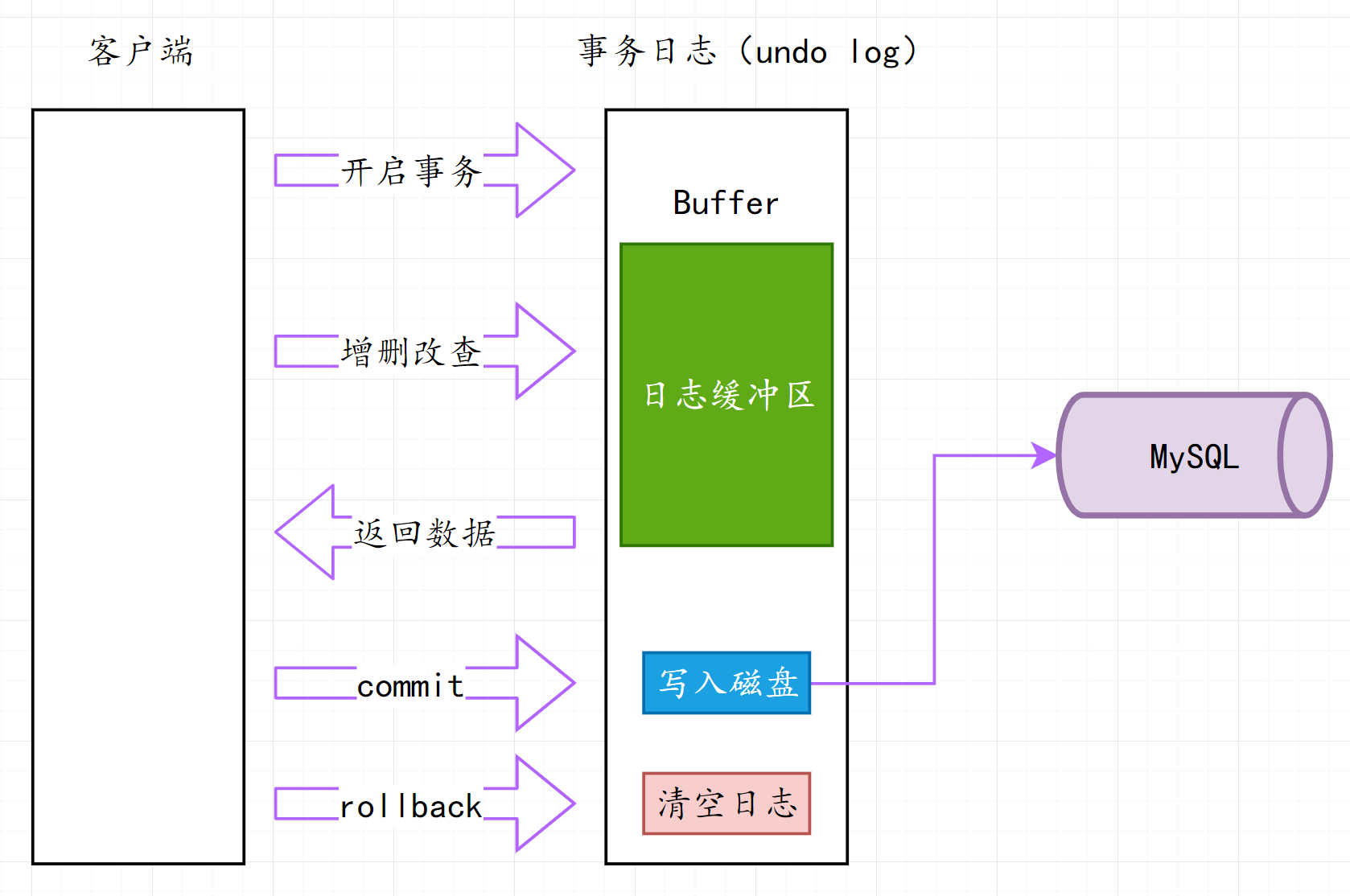
1.5.2 事务的原理解释:
- 如果没有开启事务,用户不使用日志文件,而是直接写到数据库
- 如果查询,数据从表中查询出来以后,经过日志文件加工以后返回。
- 如果回滚,清除日志文件,不会写到数据库中。
1.6 回滚点
1.6.1 什么是回滚点
在某些成功的操作完成之后,后续的操作有可能成功有可能失败,但是不管成功还是失败,前面操作都已经成功,可以在当前成功的位置设置一个回滚点。可以供后续失败操作返回到该位置,而不是返回所有操作,这个点称之为回滚点。
1.6.2 回滚点的操作语句
| 回滚点的操作语句 | 语句 |
|---|---|
| 设置回滚点 | savepoint 名字 |
| 回到回滚点 | rollback to 名字 |
1.6.3 具体操作:
- 将数据还原到1000
- 开启事务
- 让a账号减2次钱,每次10块
- 设置回滚点:savepoint p1;
- 让a账号减2次钱,每次10块
- 回到回滚点:rollback to p1;
- 分析执行过程
1 | -- 开启事务 |
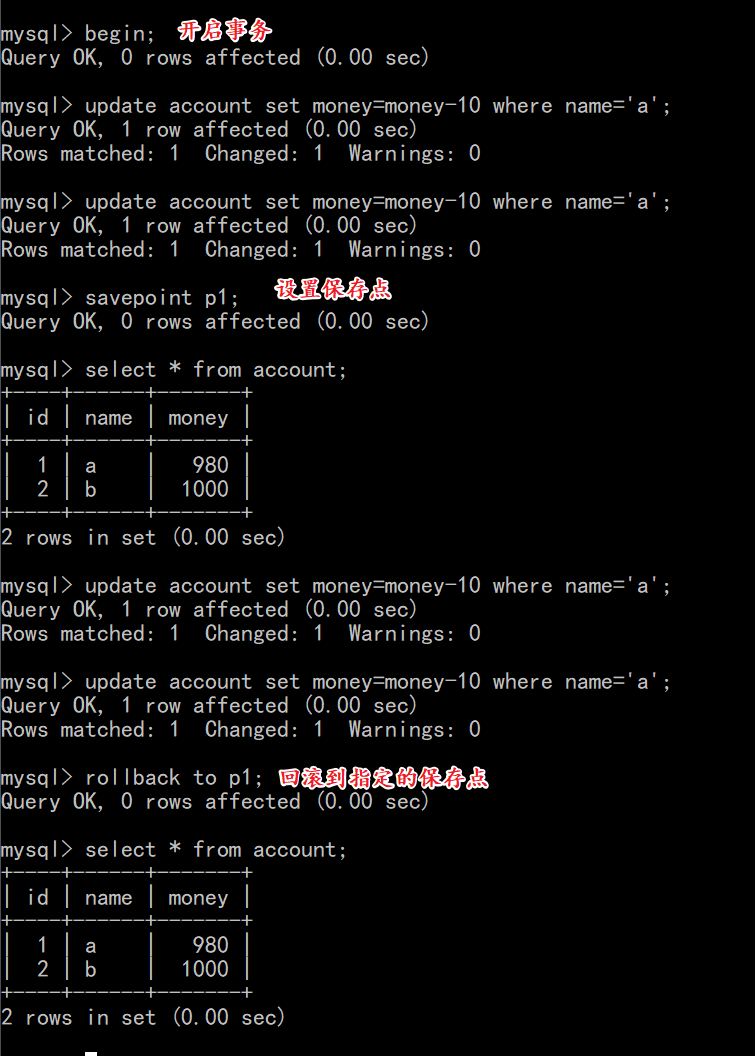
- 总结:设置回滚点可以让我们在失败的时候回到回滚点,而不是回到事务开启的时候。
二、事务的隔离级别
2.1 并发访问的三个问题
并发访问下事务产生的问题:
当同时有多个用户在访问同一张表中的记录,每个用户在访问的时候都是一个单独的事务。
事务在操作时的理想状态是:事务之间不应该相互影响,实际应用的时候会引发下面三种问题。应该尽量避免这些问题的发生。通过数据库本身的功能去避免,设置不同的隔离级别。
- 脏读: 一个事务(用户)读取到了另一个事务没有提交的数据
- 不可重复读:一个事务多次读取同一条记录,出现读取数据不一致的情况。一般因为另一个事务更新了这条记录而引发的。
- 幻读:在一次事务中,多次读取到的条数不一致
2.2 设置隔离级别
2.2.1 四种隔离级别:
| 级别 | 名字 | 隔离级别 | 脏读 | 不可重复读 | 幻读 | 数据库默认隔离级别 |
|---|---|---|---|---|---|---|
| 1 | 读未提交 | read uncommitted | 是 | 是 | 是 | |
| 2 | 读已提交 | read committed | 否 | 是 | 是 | Oracle和SQL Server |
| 3 | 可重复读 | repeatable read | 否 | 否 | 是/否 | MySQL |
| 4 | 串行化 | serializable | 否 | 否 | 否 |
2.2.2 四种隔离级别起的作用:
1)
Read uncommitted(读未提交): 简称RU隔离级别,所有事务中的并发访问问题都会发生,读取的是其他事务没有提交的数据2)
Read committed(读已提交):简称RC隔离级别,会引发不可重复读和幻读的问题,读取的永远是其他事务提交的数据3)
Repeatable read(可重复读):简称RR隔离级别,会引发幻读的问题,一次事务读取到的同一行数据,永远是一样4)
Serializable(串行化): 可以避免所有事务产生的并发访问的问题 效率及其低下
2.3 安全和性能对比
- 隔离级别越高,安全性就越高。
- 隔离级别越高,性能越低。
2.4 MySQL相关的命令:
查询全局事务隔离级别
1 | mysql> select @@tx_isolation; |
设置全局事务隔离级别
1 | set global transaction isolation level 四种隔离; -- 服务器只要不关闭一直有效 |
修改隔离级别后需要重启会话
2.5 脏读
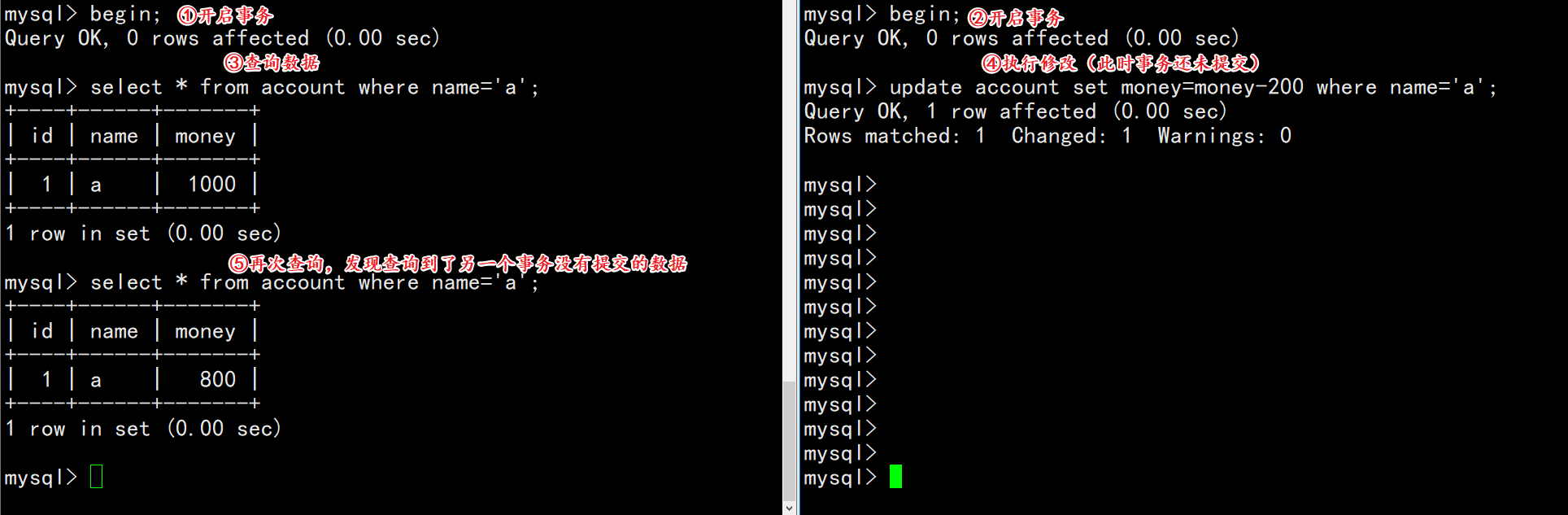
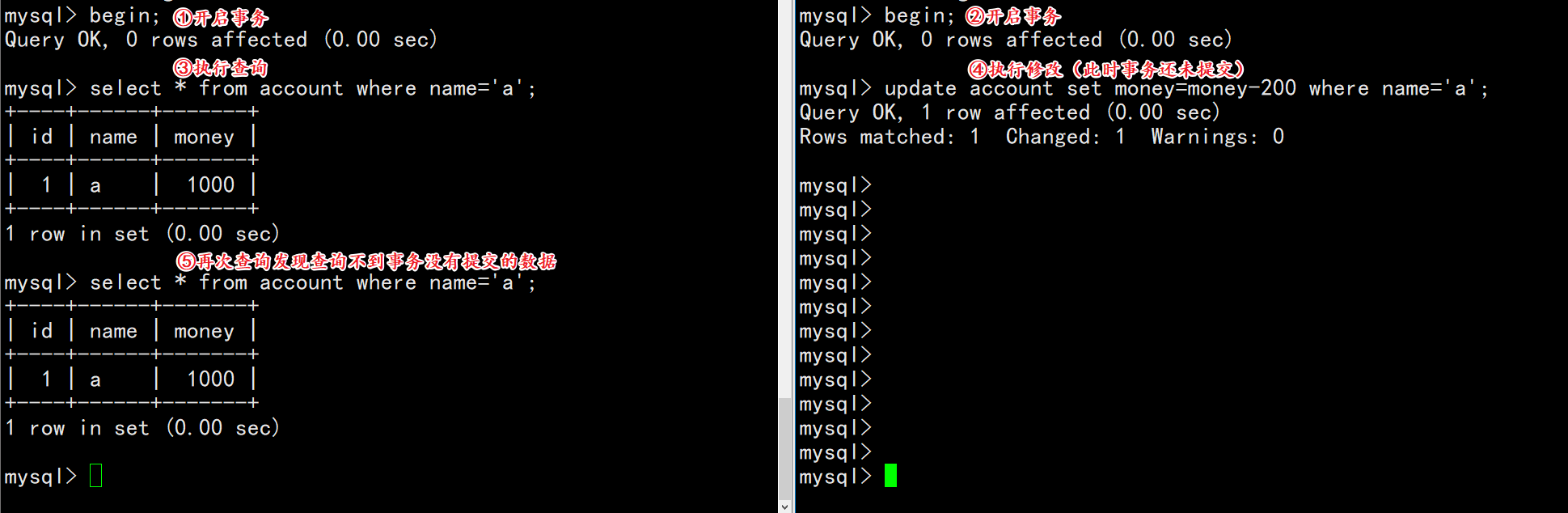
在并发情况下,一个事务读取到另一个事务没有提交的数据,这个数据称之为脏数据,此次读取也称为脏读。
我们知道,只有read uncommitted(读未提交)的隔离级别才会引发脏读。
- 将MySQL的事务隔离级别设置为
read committed(读已提交):
1 | mysql> set global transaction isolation level read uncommitted; |
将数据还原:
2.5.1 脏读演示
| session-01 | session-02 |
|---|---|
| begin; | |
| begin; | |
| select * from account where name=’a’; | |
| update account set money=money-200 where name=’a’; | |
| select * from account where name=’a’; | |
| rollback; |
观察变化:
2.5.2 解决脏读
将全局的隔离级别进行提升
- 打开命令行a,设置全局的隔离级别为read committed:
1 | set global transaction isolation level read committed; |
再次执行:
| session-01 | session-02 |
|---|---|
| begin; | |
| begin; | |
| select * from account where name=’a’; | |
| update account set money=money-200 where name=’a’; | |
| select * from account where name=’a’; | |
| rollback; |
观察变化:
2.6 不可重复读
概念: 在同一个事务中的多次查询应该出现相同的结果,两次读取不能出现不同的结果。
2.6.1 和脏读的区别:
脏读是读取前一事务未提交的脏数据,不可重复读是重复读取了前一事务已提交的数据,但2次读取的结果不同。
应用场景:比如银行程序需要将查询结果分别输出到电脑屏幕和写到文件中,结果在一个事务中针对输出的目的地,两次输出结果却不一致,导致文件和屏幕中的结果不同,银行工作人员就不知道以哪个为准了。
2.6.2 不可重复读演示
1). 将数据进行恢复,并关闭窗口重新登录。
1 | update account set money=1000; |
| session-01 | session-02 |
|---|---|
| begin; | |
| begin; | |
| select * from account where name=’a’; | |
| update account set money=money-200 where name=’a’; | |
| commit; | |
| select * from account where name=’a’; |
观察变化:
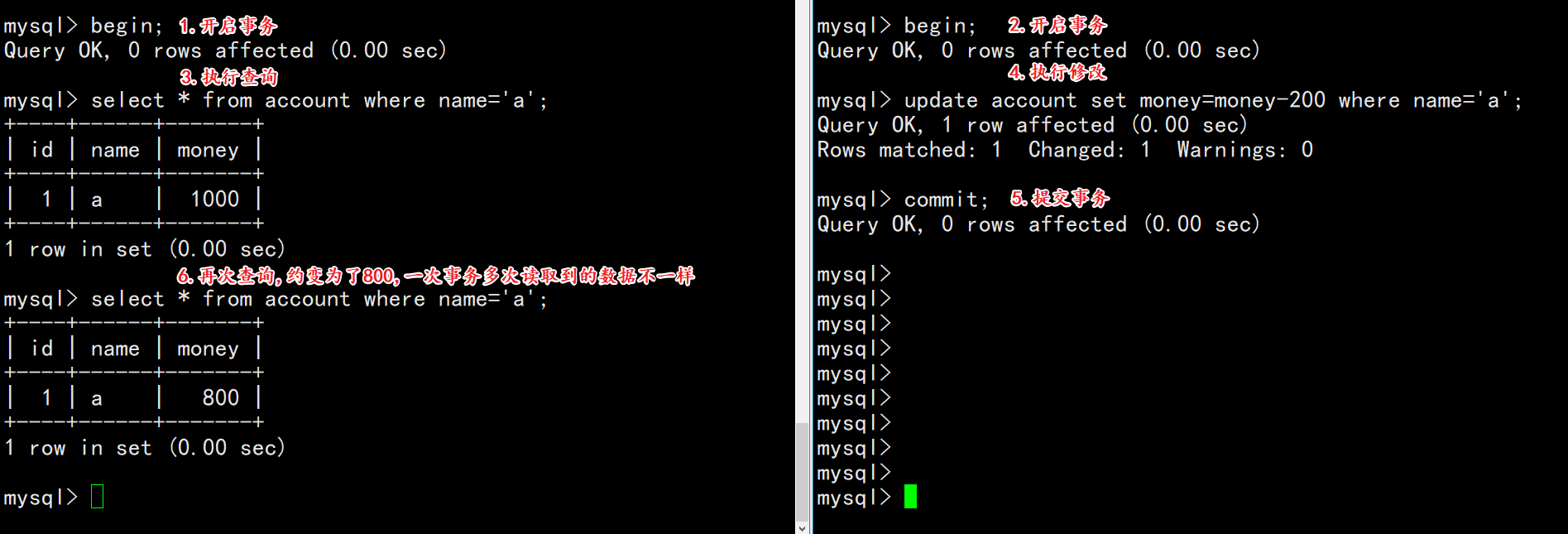
两次查询输出的结果不同,到底哪次是对的?
2.6.3 解决不可重复读
1)将数据进行恢复
1 | update account set money=1000; |
记得要重启窗口
| session-01 | session-02 |
|---|---|
| begin; | |
| begin; | |
| select * from account where name=’a’; | |
| update account set money=money-200 where name=’a’; | |
| commit; | |
| select * from account where name=’a’; |
观察变化:
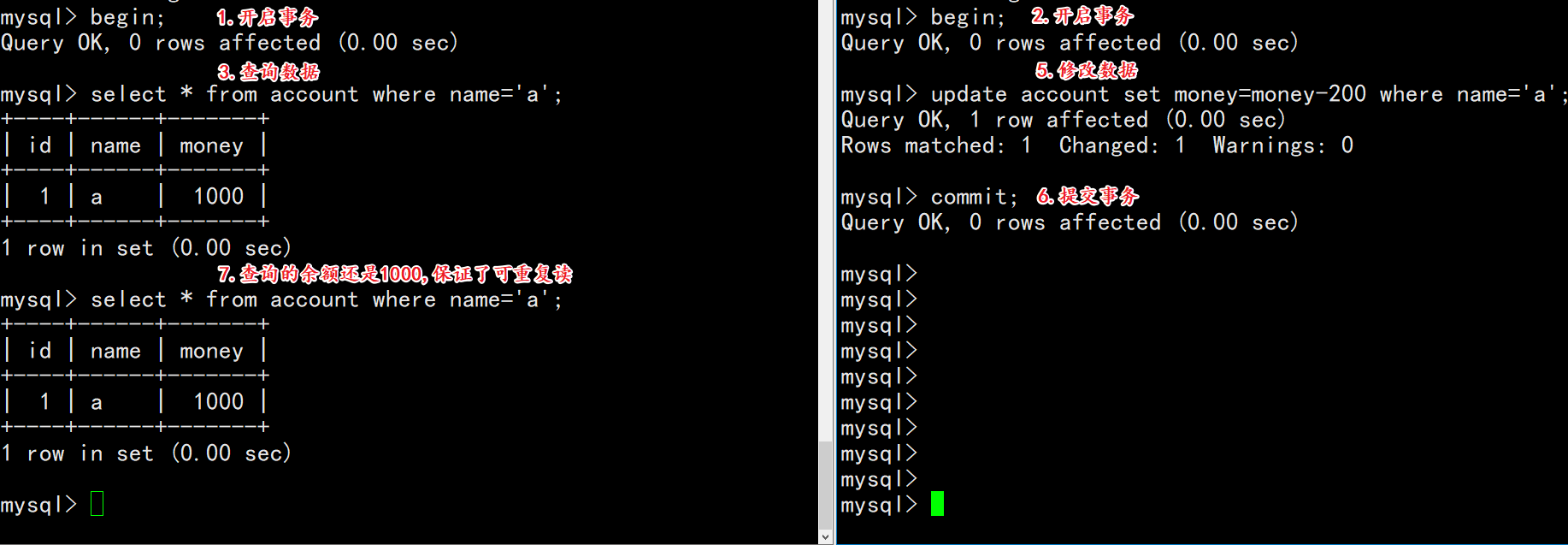
结论:为了保存多次查询数据一致,必须使用repeatable read隔离级别
2.7 幻读
概念:一次事务多次读取到的条数不一致而引发的问题;
在InnoDB(暂时理解是MySQL)中幻读在很多地方都得到了解决,但在一些特殊的情况下,还是会引发幻读问题;
为什么有的情况下能解决,有的情况下解决不了?因为一次事务多次读取到的条数不一致会导致有很多情况发生!
2.7.1 幻读解决情况1):
还原数据:
1 | update account set money=1000; |
记得重启客户端
| session-01 | session-02 |
|---|---|
| begin; | |
| begin; | |
| select * from account; | |
| insert into account values(3,’c’,1000); | |
| commit; | |
| select * from account; |
观察变化:
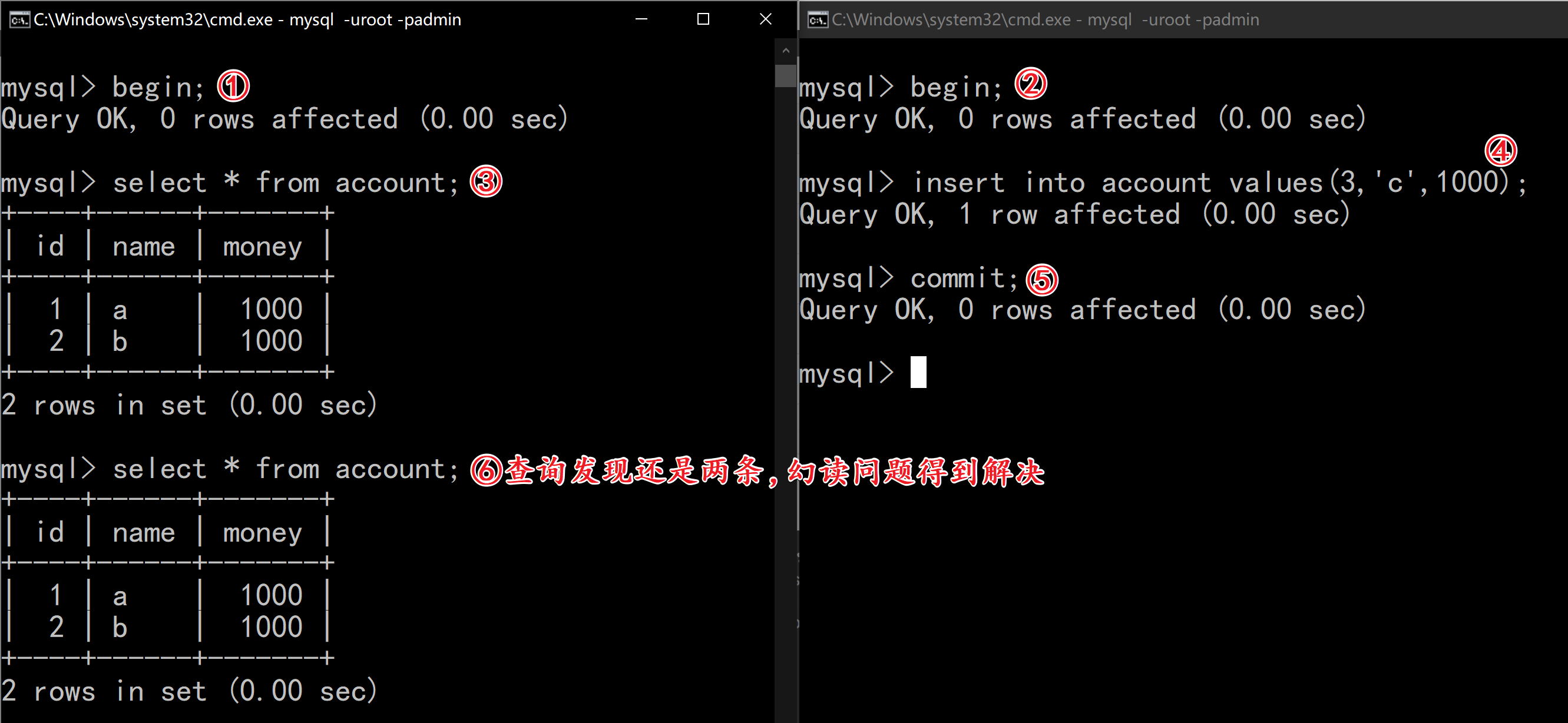
幻读问题得到解决
2.7.2 幻读解决情况2):
还原数据
案例:
| session-01 | session-02 |
|---|---|
| begin; | |
| begin; | |
| select sum(money) from account; | |
| insert into account values(3,’c’,1000); | |
| commit; | |
| select sum(money) from account; |
观察变化:
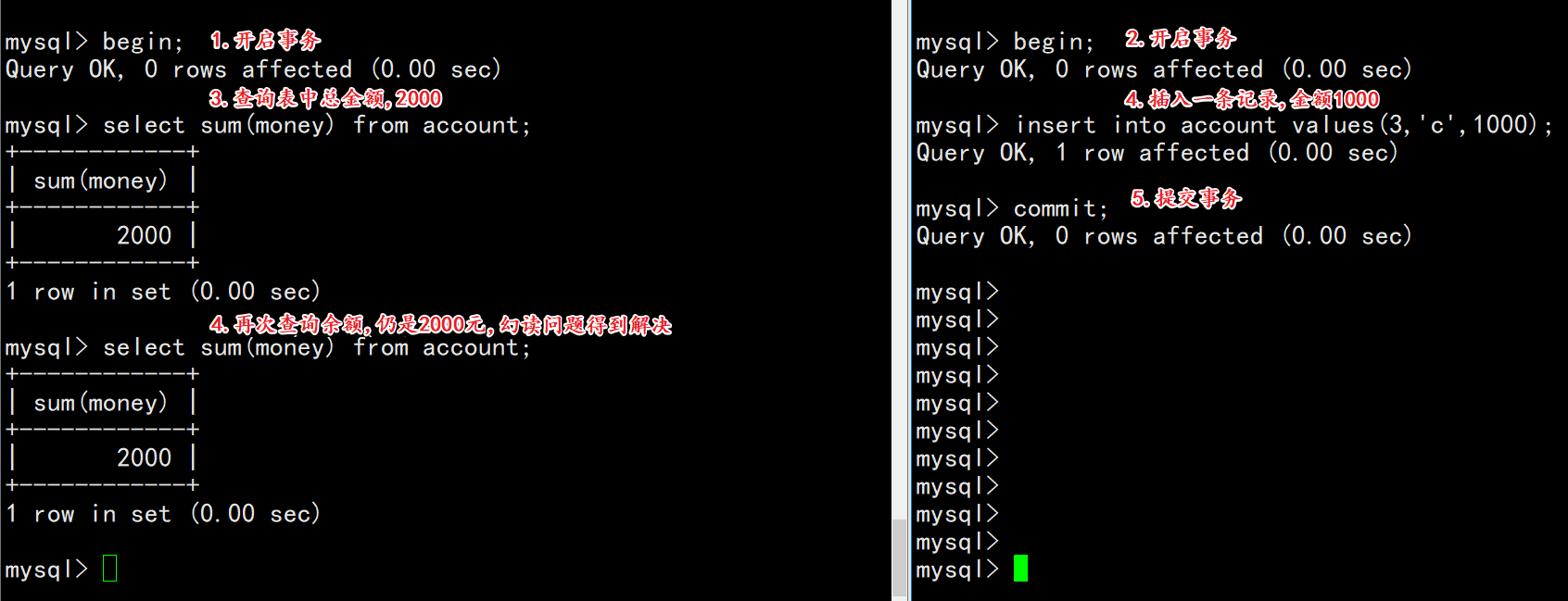
2.7.3 幻读问题出现情况1):
还原数据
- 案例:
| session-01 | session-02 |
|---|---|
| begin; | |
| begin; | |
| select count(id) from account; | |
| insert into account values(3,’c’,1000); | |
| commit; | |
| select count(id) from account; | |
| update account set money=0; | |
| select count(id) from account; |
观察变化:
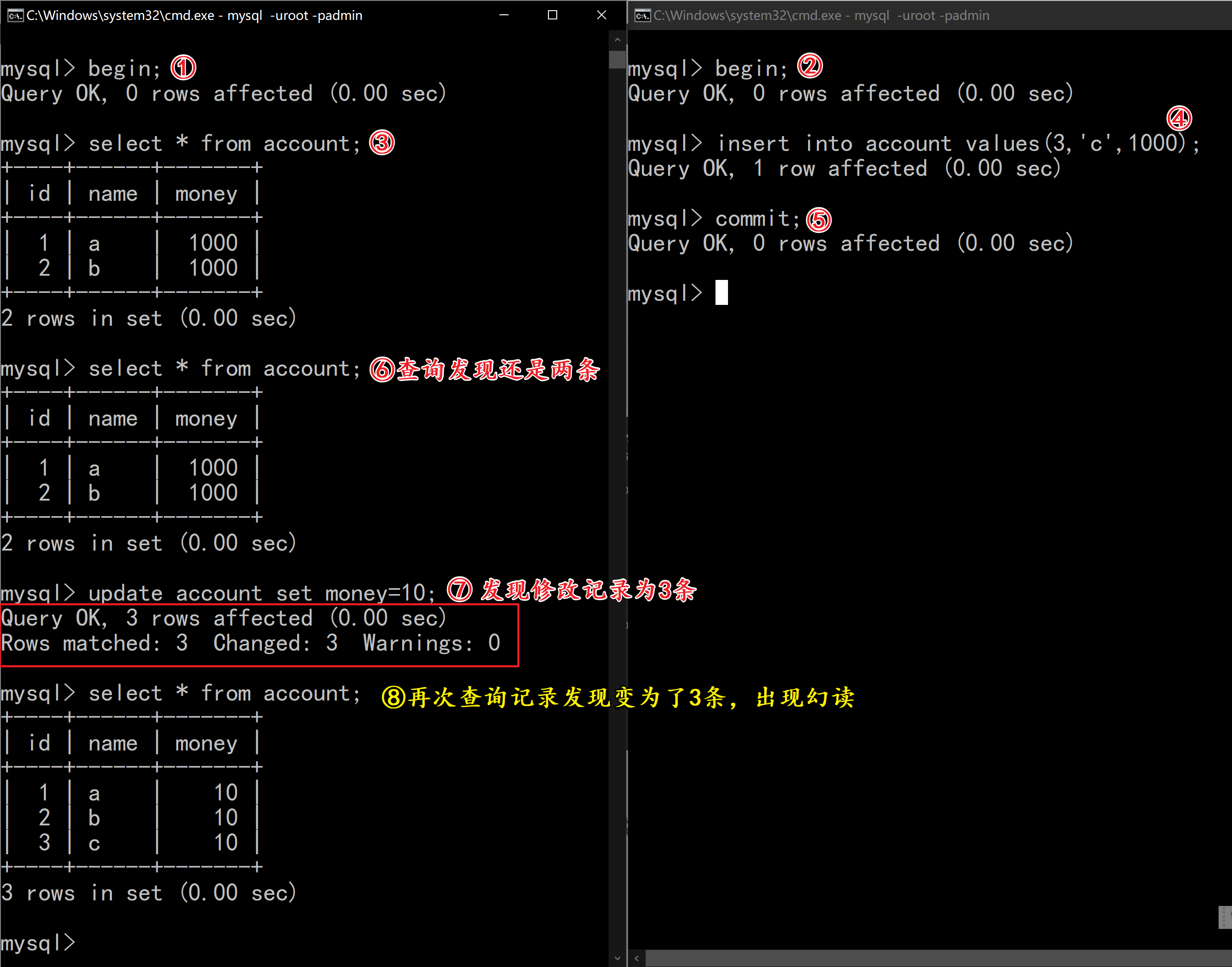
2.7.3 特殊情况:
还原数据
- 案例:
| session-01 | session-02 |
|---|---|
| begin; | |
| begin; | |
| select * from account; | |
| select * from account; | |
| insert into account values(3,”c”,1000); | |
| commit; | |
| select * from account; | |
| insert into account values(3,”c”,1000); |
观察变化:
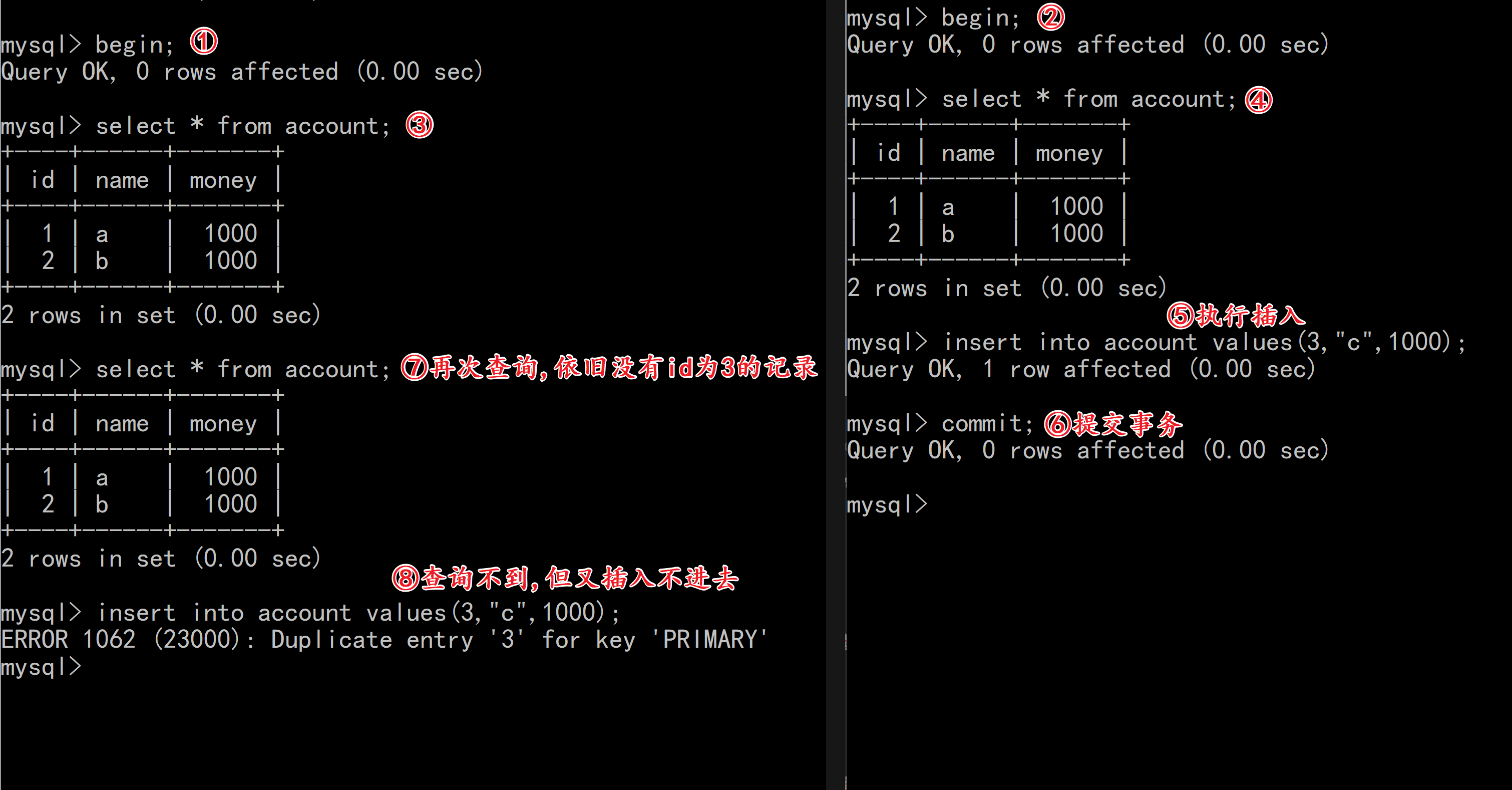
严格意义来说,上述案例是MySQL的快照机制导致的,不能算幻读;关于幻读我们理解概念就行,即:两次读取到的条数不一致!这就是幻读
2.9 串行化
2.9.1 概念
想要彻底的解决幻读,那么我们必须再把隔离级别调高,数据库的最高隔离级别为串行化(serializable)
串行化相当于锁表操作,即一个事务如果操作了某张表(增加、删除、修改),那么就不允许其他任何事务操作此表,也不允许查询,等第一个事务提交或者回滚之后才可以操作,这样做效率及其低下,因此一般不会采用serializable隔离级别
2.9.2 串行化演示
- 开启一个银行窗口
1 | -- 还原数据 |

在串行化隔离级别中,相当于锁表的操作,在一个事务对表进行任何的insert/update/delete等操作时,其他事务均不可对其进行操作;在读写上是串行的,并发能力极差;
三、JDBC事务的处理
之前我们是使用MySQL的命令来操作事务。接下来我们使用JDBC来操作银行转账的事务。
3.1 准备数据
1 | CREATE TABLE account ( |
3.2 API介绍
| Connection接口中与事务有关的方法 | 说明 |
|---|---|
| void setAutoCommit(boolean autoCommit) | 设置为false,表示开启事务 |
| void commit() | 提交事务 |
| void rollback() | 回滚事务 |
3.3 开发步骤
- 先试一下没有事务的转账情况
- 获取连接
- 获取到PreparedStatement
- 使用PreparedStatement执行两次更新操作
- 最后关闭资源
- 使用事务的情况
- 获取连接
- 开启事务
- 获取到PreparedStatement
- 使用PreparedStatement执行两次更新操作
- 正常情况下提交事务
- 出现异常回滚事务
- 最后关闭资源
- 案例代码
1 | package com.dfbz.demo; |
四、触发器和级联操作
4.1 触发器
4.1.1 触发器介绍
触发器是与表有关的数据库对象,指在 insert/update/delete 之前或之后,触发并执行触发器中定义的SQL语句集合。触发器的这种特性可以协助应用在数据库端确保数据的完整性 , 日志记录 , 数据校验等操作 。
- MySQL中触发器共有3种:
| 触发器类型 | NEW和OLD的使用 |
|---|---|
| insert触发器 | NEW 表示将要或者已经新增的数据 |
| update触发器 | OLD 表示修改之前的数据 , NEW 表示将要或已经修改后的数据 |
| delete触发器 | OLD 表示将要或者已经删除的数据 |
使用别名 OLD 和 NEW 来引用触发器中发生变化的记录内容
4.1.2 触发器语法
1 | create trigger trigger_name [after/before] [insert/update/delete] |
**after:**在插入表之后执行
**before:**在插入表之前执行(两种触发器效果一致)
建立一张日志表,存储日志
1 | CREATE TABLE log ( |
- insert触发器
1 | create trigger test1 after insert |
- update触发器
1 | create trigger test2 after update |
- delete触发器
1 | create trigger test3 after delete |
- 查看当前数据库中的触发器
1 | show triggers; |
- 删除触发器
1 | drop trigger trigger_name; |
4.2 级联
我们在表与表之间存在关系时,一般都是通过外键来关联关系的,外键维护着我们表与表之间的关系,级联就是当一方数据发生表更时(delete、update),另一方的数据应该保持着何种关联,是删除还是一起修改,还是置空呢?
我们把原来的数据库删除,重新创建:
1 | DROP TABLE IF EXISTS `class`; |
4.2.1 级联的种类
- 删除级联:
on delete set null:如果主表有删除,那么从表的数据都为nullon delete cascade:如果主表有删除,那么从表的数据也删除on delete restrict:如果设置该值,主表不允许做删除操作(默认的外键行为)on delete no action:即如果存在从数据,不允许删除主数据(和restrict类似)。
- 修改级联:
on update set null:如果主表有更新,那么从表的数据都为nullon update cascade:如果主表有更新,那么从表的数据也更新on update restrict:如果设置该值,主表不允许做更新操作(默认的外键行为)on update no action:如果从表存在对应数据,不允许更新主表数据(和restrict类似)。
4.2.2 操作外键
1 | -- 禁用外键 |
- 创建外键:
1 | -- 建表时写(1): |
- 删除外键:
1 | alter table student drop foreign key stu_fk_1; |
五、数据库的三大范式
5.1 第一范式
概念:第一范式强调每一列的原子性,每列的数据必须保证其原子性,即每列的数据必须细化到不可再拆分
案例:
| 学号 | 姓名 | 班级 |
|---|---|---|
| 001 | 张三 | Java01班 |
| 002 | 李四 | Java02班 |
| 003 | 王五 | UI01班 |
| 004 | 赵六 | 产品02班 |
在上述表中,班级字段存在数据冗余,如果我们想统计Java学科的人数或者01班级的人数岂不是很尴尬?根据第一大范式条件必须保证每一列数据的原子性,我们可细化分如下:
| 学号 | 姓名 | 学科 | 班级 |
|---|---|---|---|
| 001 | 张三 | Java | 01班 |
| 002 | 李四 | Java | 02班 |
| 003 | 王五 | UI | 01班 |
| 004 | 赵六 | 产品 | 02班 |
5.2 第二范式
概念:在满足第一范式的条件下,每一列的数据都完全依赖于主键,不产生局部依赖,每张表都只描述一件事物,每一列都和主键相关联
也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
案例
借阅表:
| 借阅ID | 书籍ID | 书籍名称 | 出版社 | 数量 | 学号 | 学生姓名 | 手机号 |
|---|---|---|---|---|---|---|---|
| 001 | 1 | 高性能MySQL | 清华大学出版社 | 1 | zs-001 | 张三 | 110 |
| 001 | 2 | MySQL技术内幕 | 北京大学出版社 | 2 | ls-002 | 李四 | 120 |
缺点:大量重复数据,每存一条数据都会有重复的出版社、年龄、手机号等重复数据
根据第二大范式,表中的数据不能产生局部依赖,上述表中很明显出版社、书籍名称依赖于书籍ID,而学生姓名、手机号等依赖于学号
根据第二范式细化:拆分成学生表、书籍表、借阅表
学生信息表:
| 学号 | 姓名 | 年龄 | 手机号 |
|---|---|---|---|
| zs-001 | 张三 | 21 | 110 |
| ls-002 | 李四 | 22 | 120 |
书籍表:
| 书籍ID | 书籍名称 | 出版社 |
|---|---|---|
| 1 | 高性能MySQL | 清华大学出版社 |
| 2 | MySQL技术内幕 | 北京大学出版社 |
借阅表:
| 借阅ID | 借阅书籍ID | 借阅人学号 | 借阅数量 |
|---|---|---|---|
| 001 | 1 | zs-001 | 1 |
| 002 | 2 | zs-002 | 2 |
5.3 第三范式
概念:在满足第二范式的条件下,表中的每一列不存在传递依赖,每列都直接依赖于主键
案例:
| ID | 姓名 | 年龄 | 所属部门 | 部门地点 |
|---|---|---|---|---|
| 001 | 张三 | 21 | 研发部 | 石家庄 |
| 002 | 李四 | 22 | 销售部 | 郑州 |
| 003 | 王五 | 25 | 研发部 | 济南 |
根据第三范式,每一列应该直接依赖于主键
我们应该拆分成一张用户表和一张部门表,通过建立外键来建立两表之间的关系
部门表
| 部门id | 部门名称 | 部门地点 | 部门简码 | 部门等级 |
|---|---|---|---|---|
| 001 | 研发部 | 石家庄 | dev | 1 |
| 002 | 行政部 | 郑州 | admin | 2 |
| 003 | 销售部 | 济南 | sale | 2 |
员工表:
| ID | 姓名 | 年龄 | 部门ID |
|---|---|---|---|
| 001 | 张三 | 21 | 001 |
| 002 | 李四 | 22 | 002 |
| 003 | 王五 | 25 | 001 |
5.4 反范式化
一般我们设计表都会按照数据库的三大范式,但是在某些情况下我们查询的数据在多张表中,例如我们需要查询员工的信息并且希望带出员工的部门名称,这个时候我们必须使用join关联表查询,如果这些数据是查询非常频繁的,那么无疑会降低数据库的读性能
反范式设计表:
| 编号 | 姓名 | 年龄 | 部门id | 部门名称 |
|---|---|---|---|---|
| 001 | 张三 | 21 | 001 | 研发部 |
| 002 | 李四 | 22 | 002 | 运营部 |
此时数据都在一张表,查询也不用join关联查询,以此提高读取性能
部门表:
| 部门id | 部门名称 | 部门地点 | 部门简码 | 部门等级 |
|---|---|---|---|---|
| 001 | 研发部 | 石家庄 | dev | 1 |
| 002 | 运营部 | 郑州 | admin | 2 |
| 003 | 销售部 | 济南 | sale | 2 |
5.5 过分范式化带来的弊端
- 1)过分的满足第一范式设计:即保证每一列的原子性,会给表带来非常多的列;
| ID | 姓名 | 年龄 | 地址 |
|---|---|---|---|
| 001 | 张三 | 20 | 江西省南昌市洪城路128号8栋601 |
| 002 | 李四 | 23 | 江西省南昌市青云谱区洪都大道118号9栋301 |
过分满足第一范式:
| ID | 姓名 | 年龄 | 省份 | 城市 | 县区 | 道路 | 牌号 |
|---|---|---|---|---|---|---|---|
| 001 | 张三 | 20 | 江西省 | 南昌市 | 西湖区 | 洪城路 | 128号 |
| 002 | 李四 | 23 | 江西省 | 南昌市 | 青云谱区 | 洪都大道 | 118号 |
过分的满足第一范式会带来非常多的列,导致查询性能下降
- 2)过分的满足第三范式:表中的每一列不存在传递依赖,每列都直接依赖于主键
反范式化明显就不符合第三范式