Linux 命令
Linux 命令
文件管理
cat
cat命令用于连接文件并打印到标准输出设备上。
1 | 语法格式 |
参数说明
-n 或 –number:由 1 开始对所有输出的行数编号。
-b 或 –number-nonblank:和 -n 相似,只不过对于空白行不编号。
-s 或 –squeeze-blank:当遇到有连续两行以上的空白行,就代换为一行的空白行。
-v 或 –show-nonprinting:使用 ^ 和 M- 符号,除了 LFD 和 TAB 之外。
-E 或 –show-ends : 在每行结束处显示 $。
-T 或 –show-tabs: 将 TAB 字符显示为 ^I。
-A, –show-all:等价于 -vET。
**-e:**等价于”-vE”选项;
**-t:**等价于”-vT”选项
实例
1 | 把 textfile1 的文档内容加上行号后输入 textfile2 这个文档里 |
注意:
- OUTFILE 指输出的镜像文件名
- IMG_FILE 指镜像文件
- 若从镜像文件写回 device 时,device 容量需与相当
- 通常用制作开机磁片
chattr
chattr命令用于改变文件属性
这项指令可改变存放在ext2文件系统上的文件或目录属性,这些属性共有以下8种模式:
- a:让文件或目录仅供附加用途。
- b:不更新文件或目录的最后存取时间。
- c:将文件或目录压缩后存放。
- d:将文件或目录排除在倾倒操作之外。
- i:不得任意更动文件或目录。
- s:保密性删除文件或目录。
- S:即时更新文件或目录。
- u:预防意外删除。
1 | 语法格式 |
参数说明
-R 递归处理,将指定目录下的所有文件及子目录一并处理。
-v<版本编号> 设置文件或目录版本。
-V 显示指令执行过程。
+<属性> 开启文件或目录的该项属性。
-<属性> 关闭文件或目录的该项属性。
=<属性> 指定文件或目录的该项属性。
实例
1 | 用chattr命令防止系统中某个关键文件被修改 |
chgrp
chgrp命令用于变更文件或目录的所属群组
与 chown 命令不同,chgrp 允许普通用户改变文件所属的组,只要该用户是该组的一员。
在 UNIX 系统家族里,文件或目录权限的掌控以拥有者及所属群组来管理。您可以使用 chgrp 指令去变更文件与目录的所属群组,设置方式采用群组名称或群组识别码皆可。
1 | 语法格式 |
参数说明
-c 或 –changes:效果类似”-v”参数,但仅回报更改的部分。
-f 或 –quiet 或 –silent: 不显示错误信息。
-h 或 –no-dereference: 只对符号连接的文件作修改,而不改动其他任何相关文件。
-R 或 –recursive: 递归处理,将指定目录下的所有文件及子目录一并处理。
-v 或 –verbose: 显示指令执行过程。
–help: 在线帮助。
–reference=<参考文件或目录>: 把指定文件或目录的所属群组全部设成和参考文件或目录的所属群组相同。
–version: 显示版本信息。
实例
1 | 改变文件的群组属性 |
chmod
chmod命令是控制用户对文件的权限的命令
Linux/Unix 的文件调用权限分为三级 : 文件所有者(Owner)、用户组(Group)、其它用户(Other Users)。
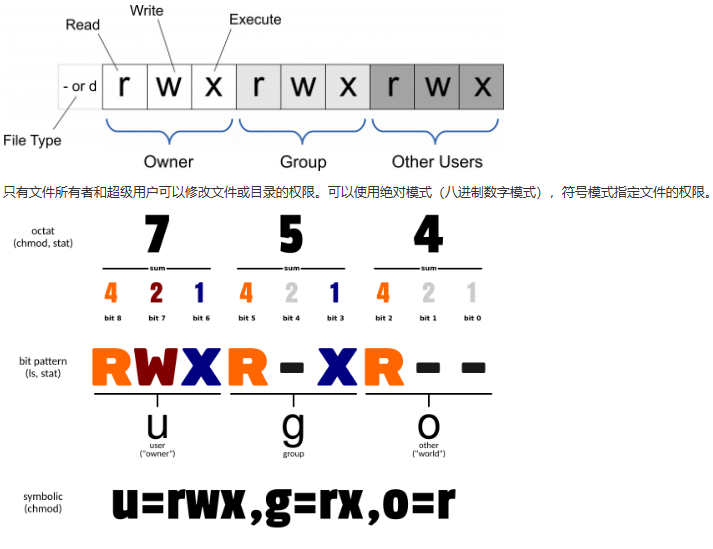
1 | 语法结构 |
参数说明
mode : 权限设定字串,格式如下
1 | [ugoa...][[+-=][rwxX]...][,...] |
其中:
- u 表示该文件的拥有者,g 表示与该文件的拥有者属于同一个群体(group)者,o 表示其他以外的人,a 表示这三者皆是。
- + 表示增加权限、- 表示取消权限、= 表示唯一设定权限。
- r 表示可读取,w 表示可写入,x 表示可执行,X 表示只有当该文件是个子目录或者该文件已经被设定过为可执行。
其他参数说明:
- -c : 若该文件权限确实已经更改,才显示其更改动作
- -f : 若该文件权限无法被更改也不要显示错误讯息
- -v : 显示权限变更的详细资料
- -R : 对目前目录下的所有文件与子目录进行相同的权限变更(即以递归的方式逐个变更)
- –help : 显示辅助说明
- –version : 显示版本
实例
1 | 将文件 file1.txt 设为所有人皆可读取 |
chown
chown命令用于设置文件所有者和文件关联组的命令
利用 chown 将指定文件的拥有者改为指定的用户或组,用户可以是用户名或者用户 ID,组可以是组名或者组 ID,文件是以空格分开的要改变权限的文件列表,支持通配符。
chown 需要超级用户 root 的权限才能执行此命令。
只有超级用户和属于组的文件所有者才能变更文件关联组。非超级用户如需要设置关联组可能需要使用 chgrp 命令。
1 | 语法结构 |
参数说明
- user : 新的文件拥有者的使用者 ID
- group : 新的文件拥有者的使用者组(group)
- -c : 显示更改的部分的信息
- -f : 忽略错误信息
- -h :修复符号链接
- -v : 显示详细的处理信息
- -R : 处理指定目录以及其子目录下的所有文件
- –help : 显示辅助说明
- –version : 显示版本
实例
1 | 把 /var/run/httpd.pid 的所有者设置 root |
cksum
cksum命令用于检查文件的CRC是否正确。确保文件从一个系统传输到另一个系统的过程中不被损坏。
CRC是一种排错检查方式,该校验法的标准由CCITT所指定,至少可检测到99.998%的已知错误。
指定文件交由指令”cksum”进行校验后,该指令会返回校验结果供用户核对文件是否正确无误。若不指定任何文件名称或是所给予的文件名为”-“,则指令”cksum”会从标准输入设备中读取数据。
1 | 语法结构 |
说明参数
- –help:在线帮助。
- –version:显示版本信息。
- 文件…:需要进行检查的文件路径
实例
1 | 使用指令"cksum"计算文件"testfile1"的完整性,输入如下命令 |
上面的输出信息中,”1263453430”表示校验码,”78”表示字节数。
**注意:**如果文件中有任何字符被修改,都将改变计算后CRC校验码的值。
cmp
cmp命令用于比较两个文件是否有差异。
当相互比较的两个文件完全一样时,则该指令不会显示任何信息。若发现有所差异,预设会标示出第一个不同之处的字符和列数编号。若不指定任何文件名称或是所给予的文件名为”-“,则cmp指令会从标准输入设备读取数据。
1 | 语法结构 |
参数说明
- -c或–print-chars 除了标明差异处的十进制字码之外,一并显示该字符所对应字符。
- -i<字符数目>或–ignore-initial=<字符数目> 指定一个数目。
- -l或–verbose 标示出所有不一样的地方。
- -s或–quiet或–silent 不显示错误信息。
- -v或–version 显示版本信息。
- –help 在线帮助。
实例
1 | 要确定两个文件是否相同,请输入 |
如果显示消息 cmp: EOF on prog.o.bak,则 prog.o 的第一部分与 prog.o.bak 相同,但在 prog.o 中还有其他数据。
diff
diff命令用于比较文件的差异。
diff 以逐行的方式,比较文本文件的异同处。如果指定要比较目录,则 diff 会比较目录中相同文件名的文件,但不会比较其中子目录。
1 | 语法结构 |
参数说明
- -<行数> 指定要显示多少行的文本。此参数必须与-c或-u参数一并使用。
- -a或–text diff预设只会逐行比较文本文件。
- -b或–ignore-space-change 不检查空格字符的不同。
- -B或–ignore-blank-lines 不检查空白行。
- -c 显示全部内文,并标出不同之处。
- -C<行数>或–context<行数> 与执行”-c-<行数>”指令相同。
- -d或–minimal 使用不同的演算法,以较小的单位来做比较。
- -D<巨集名称>或ifdef<巨集名称> 此参数的输出格式可用于前置处理器巨集。
- -e或–ed 此参数的输出格式可用于ed的script文件。
- -f或-forward-ed 输出的格式类似ed的script文件,但按照原来文件的顺序来显示不同处。
- -H或–speed-large-files 比较大文件时,可加快速度。
- -I<字符或字符串>或–ignore-matching-lines<字符或字符串> 若两个文件在某几行有所不同,而这几行同时都包含了选项中指定的字符或字符串,则不显示这两个文件的差异。
- -i或–ignore-case 不检查大小写的不同。
- -l或–paginate 将结果交由pr程序来分页。
- -n或–rcs 将比较结果以RCS的格式来显示。
- -N或–new-file 在比较目录时,若文件A仅出现在某个目录中,预设会显示:
- Only in目录:文件A若使用-N参数,则diff会将文件A与一个空白的文件比较。
- -p 若比较的文件为C语言的程序码文件时,显示差异所在的函数名称。
- -P或–unidirectional-new-file 与-N类似,但只有当第二个目录包含了一个第一个目录所没有的文件时,才会将这个文件与空白的文件做比较。
- -q或–brief 仅显示有无差异,不显示详细的信息。
- -r或–recursive 比较子目录中的文件。
- -s或–report-identical-files 若没有发现任何差异,仍然显示信息。
- -S<文件>或–starting-file<文件> 在比较目录时,从指定的文件开始比较。
- -t或–expand-tabs 在输出时,将tab字符展开。
- -T或–initial-tab 在每行前面加上tab字符以便对齐。
- -u,-U<列数>或–unified=<列数> 以合并的方式来显示文件内容的不同。
- -v或–version 显示版本信息。
- -w或–ignore-all-space 忽略全部的空格字符。
- -W<宽度>或–width<宽度> 在使用-y参数时,指定栏宽。
- -x<文件名或目录>或–exclude<文件名或目录> 不比较选项中所指定的文件或目录。
- -X<文件>或–exclude-from<文件> 您可以将文件或目录类型存成文本文件,然后在=<文件>中指定此文本文件。
- -y或–side-by-side 以并列的方式显示文件的异同之处。
- –help 显示帮助。
- –left-column 在使用-y参数时,若两个文件某一行内容相同,则仅在左侧的栏位显示该行内容。
- –suppress-common-lines 在使用-y参数时,仅显示不同之处。
实例
1 | 比较两个文件 |
说明:
- “|”表示前后2个文件内容有不同
- “<”表示后面文件比前面文件少了1行内容
- “>”表示后面文件比前面文件多了1行内容
diffstat
diffstat命令根据diff的比较结果,显示统计数字。
diffstat读取diff的输出结果,然后统计各文件的插入,删除,修改等差异计量。
1 | 语法结构 |
参数说明
- -n<文件名长度> 指定文件名长度,指定的长度必须大于或等于所有文件中最长的文件名。
- -p<文件名长度> 与-n参数相同,但此处的<文件名长度>包括了文件的路径。
- -w 指定输出时栏位的宽度。
- -V 显示版本信息。
实例
1 | 用户也可以直接使用"|"将diff指令所输出的结果直接送给diffstat指令进行统计结果的显示。 |
从上面的文件内容显示,可以看到两个文件内容的差别。现在来运行刚才的命令,对文件比较的结果进行统计显示,结果如下:
1 | testfile | 2 +- #统计信息输出显示 |
file
file命令用于辨识文件类型。
1 | 语法结构 |
参数说明
- -b 列出辨识结果时,不显示文件名称。
- -c 详细显示指令执行过程,便于排错或分析程序执行的情形。
- -f<名称文件> 指定名称文件,其内容有一个或多个文件名称时,让file依序辨识这些文件,格式为每列一个文件名称。
- -L 直接显示符号连接所指向的文件的类别。
- -m<魔法数字文件> 指定魔法数字文件。
- -v 显示版本信息。
- -z 尝试去解读压缩文件的内容。
- [文件或目录…] 要确定类型的文件列表,多个文件之间使用空格分开,可以使用shell通配符匹配多个文件。
实例
1 | 显示文件类型: |
find
find 命令用于在指定目录下查找文件和目录。
它可以使用不同的选项来过滤和限制查找的结果。
1 | 语法结构 |
参数说明
path 是要查找的目录路径,可以是一个目录或文件名,也可以是多个路径,多个路径之间用空格分隔,如果未指定路径,则默认为当前目录。
expression 是可选参数,用于指定查找的条件,可以是文件名、文件类型、文件大小等等。
expression 中可使用的选项有二三十个之多,以下列出最常用的部份:
-name pattern:按文件名查找,支持使用通配符*和?。-type type:按文件类型查找,可以是f(普通文件)、d(目录)、l(符号链接)等。-size [+-]size[cwbkMG]:按文件大小查找,支持使用+或-表示大于或小于指定大小,单位可以是c(字节)、w(字数)、b(块数)、k(KB)、M(MB)或G(GB)。-mtime days:按修改时间查找,支持使用+或-表示在指定天数前或后,days 是一个整数表示天数。-user username:按文件所有者查找。-group groupname:按文件所属组查找。
find 命令中用于时间的参数如下:
-amin n:查找在 n 分钟内被访问过的文件。-atime n:查找在 n*24 小时内被访问过的文件。-cmin n:查找在 n 分钟内状态发生变化的文件(例如权限)。-ctime n:查找在 n*24 小时内状态发生变化的文件(例如权限)。-mmin n:查找在 n 分钟内被修改过的文件。-mtime n:查找在 n*24 小时内被修改过的文件。
在这些参数中,n 可以是一个正数、负数或零。正数表示在指定的时间内修改或访问过的文件,负数表示在指定的时间之前修改或访问过的文件,零表示在当前时间点上修改或访问过的文件。
例如:-mtime 0 表示查找今天修改过的文件,-mtime -7 表示查找一周以前修改过的文件。
关于时间 n 参数的说明:
- +n:查找比 n 天前更早的文件或目录。
- -n:查找在 n 天内更改过属性的文件或目录。
- n:查找在 n 天前(指定那一天)更改过属性的文件或目录。
实例
1 | 查找当前目录下名为 file.txt 的文件: |
git
git命令是文字模式下的文件管理员。
git是用来管理文件的程序,它十分类似DOS下的Norton Commander,具有互动式操作界面。它的操作方法和Norton Commander几乎一样。
1 | 语法结构 |
操作说明
- F1 :执行info指令,查询指令相关信息,会要求您输入欲查询的名称。
- F2 :执行cat指令,列出文件内容。
- F3 :执行gitview指令,观看文件内容。
- F4 :执行vi指令,编辑文件内容。
- F5 :执行cp指令,复制文件或目录,会要求您输入目标文件或目录。
- F6 :执行mv指令,移动文件或目录,或是更改其名称,会要求您输入目标文件或目录。
- F7 :执行mkdir指令,建立目录。
- F8 :执行rm指令,删除文件或目录。
- F9 :执行make指令,批处理执行指令或编译程序时,会要求您输入相关命令。
- F10 :离开git文件管理员。
gitview
gitview命令用于观看文件的内容,它会同时显示十六进制和ASCII格式的字码。
1 | 语法结构 |
参数说明
- -b 单色模式,不使用ANSI控制码显示彩色。
- -c 彩色模式,使用ANSI控制码显示色彩。
- -h 在线帮助。
- -i 显示存放gitview程序的所在位置。
- -l 不使用先前的显示字符。
- -v 显示版本信息。
实例
1 | 使用指令gitview以彩色模式观看文件"/home/ rootlocal/demo.txt"中的内容,输入如下命令: |
indent
indent命令用于调整C原始代码文件的格式。
indent可辨识C的原始代码文件,并加以格式化,以方便程序设计师阅读。
1 | 语法结构 |
参数说明
- -bad或–blank-lines-after-declarations 在声明区段或加上空白行。
- -bap或–blank-lines-after-procedures 在程序或加上空白行。
- -bbb或–blank-lines-after-block-comments 在注释区段后加上空白行。
- -bc或–blank-lines-after-commas 在声明区段中,若出现逗号即换行。
- -bl或–braces-after-if-line if(或是else,for等等)与后面执行区段的”{“不同行,且”}”自成一行。
- -bli<缩排格数>或–brace-indent<缩排格数> 设置{ }缩排的格数。
- -br或–braces-on-if-line if(或是else,for等等)与后面执行跛段的”{“不同行,且”}”自成一行。
- -bs或–blank-before-sizeof 在sizeof之后空一格。
- -c<栏数>或–comment-indentation<栏数> 将注释置于程序码右侧指定的栏位。
- -cd<栏数>或–declaration-comment-column<栏数> 将注释置于声明右侧指定的栏位。
- -cdb或–comment-delimiters-on-blank-lines 注释符号自成一行。
- -ce或–cuddle-else 将else置于”}”(if执行区段的结尾)之后。
- -ci<缩排格数>或–continuation-indentation<缩排格数> 叙述过长而换行时,指定换行后缩排的格数。
- -cli<缩排格数>或–case-indentation-<缩排格数> 使用case时,switch缩排的格数。
- -cp<栏数>或-else-endif-column<栏数> 将注释置于else与elseif叙述右侧定的栏位。
- -cs或–space-after-cast 在cast之后空一格。
- -d<缩排格数>或-line-comments-indentation<缩排格数> 针对不是放在程序码右侧的注释,设置其缩排格数。
- -di<栏数>或–declaration-indentation<栏数> 将声明区段的变量置于指定的栏位。
- -fc1或–format-first-column-comments 针对放在每行最前端的注释,设置其格式。
- -fca或–format-all-comments 设置所有注释的格式。
- -gnu或–gnu-style 指定使用GNU的格式,此为预设值。
- -i<格数>或–indent-level<格数> 设置缩排的格数。
- -ip<格数>或–parameter-indentation<格数> 设置参数的缩排格数。
- -kr或–k-and-r-style 指定使用Kernighan&Ritchie的格式。
- -lp或–continue-at-parentheses 叙述过长而换行,且叙述中包含了括弧时,将括弧中的每行起始栏位内容垂直对其排列。
- -nbad或–no-blank-lines-after-declarations 在声明区段后不要加上空白行。
- -nbap或–no-blank-lines-after-procedures 在程序后不要加上空白行。
- -nbbb或–no-blank-lines-after-block-comments 在注释区段后不要加上空白行。
- -nbc或–no-blank-lines-after-commas 在声明区段中,即使出现逗号,仍旧不要换行。
- -ncdb或–no-comment-delimiters-on-blank-lines 注释符号不要自成一行。
- -nce或–dont-cuddle-else 不要将else置于”}”之后。
- -ncs或–no-space-after-casts 不要在cast之后空一格。
- -nfc1或–dont-format-first-column-comments 不要格式化放在每行最前端的注释。
- -nfca或–dont-format-comments 不要格式化任何的注释。
- -nip或–no-parameter-indentation 参数不要缩排。
- -nlp或–dont-line-up-parentheses 叙述过长而换行,且叙述中包含了括弧时,不用将括弧中的每行起始栏位垂直对其排列。
- -npcs或–no-space-after-function-call-names 在调用的函数名称之后,不要加上空格。
- -npro或–ignore-profile 不要读取indent的配置文件.indent.pro。
- -npsl或–dont-break-procedure-type 程序类型与程序名称放在同一行。
- -nsc或–dont-star-comments 注解左侧不要加上星号(*)。
- -nsob或–leave-optional-semicolon 不用处理多余的空白行。
- -nss或–dont-space-special-semicolon 若for或while区段仅有一行时,在分号前不加上空格。
- -nv或–no-verbosity 不显示详细的信息。
- -orig或–original 使用Berkeley的格式。
- -pcs或–space-after-procedure-calls 在调用的函数名称与”{“之间加上空格。
- -psl或–procnames-start-lines 程序类型置于程序名称的前一行。
- -sc或–start-left-side-of-comments 在每行注释左侧加上星号(*)。
- -sob或–swallow-optional-blank-lines 删除多余的空白行。
- -ss或–space-special-semicolon 若for或swile区段今有一行时,在分号前加上空格。
- -st或–standard-output 将结果显示在标准输出设备。
- -T 数据类型名称缩排。
- -ts<格数>或–tab-size<格数> 设置tab的长度。
- -v或–verbose 执行时显示详细的信息。
- -version 显示版本信息。
cut
cut命令用于显示每行从开头算起 num1 到 num2 的文字。
1 | 语法结构 |
使用说明:
cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段写至标准输出。
如果不指定 File 参数,cut 命令将读取标准输入。必须指定 -b、-c 或 -f 标志之一。
参数说明
- -b :以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了 -n 标志。
- -c :以字符为单位进行分割。
- -d :自定义分隔符,默认为制表符。
- -f :与-d一起使用,指定显示哪个区域。
- -n :取消分割多字节字符。仅和 -b 标志一起使用。如果字符的最后一个字节落在由 -b 标志的 List 参数指示的
范围之内,该字符将被写出;否则,该字符将被排除
实例
1 | 当你执行who命令时,会输出类似如下的内容: |
ln
ln命令是为某一个文件在另外一个位置建立一个同步的链接。
当我们需要在不同的目录,用到相同的文件时,我们不需要在每一个需要的目录下都放一个必须相同的文件,我们只要在某个固定的目录,放上该文件,然后在 其它的目录下用ln命令链接(link)它就可以,不必重复的占用磁盘空间。
1 | 语法结构 |
命令功能
Linux文件系统中,有所谓的链接(link),我们可以将其视为档案的别名,而链接又可分为两种 : 硬链接(hard link)与软链接(symbolic link),硬链接的意思是一个档案可以有多个名称,而软链接的方式则是产生一个特殊的档案,该档案的内容是指向另一个档案的位置。硬链接是存在同一个文件系统中,而软链接却可以跨越不同的文件系统。
不论是硬链接或软链接都不会将原本的档案复制一份,只会占用非常少量的磁碟空间。
软链接:
- 1.软链接,以路径的形式存在。类似于Windows操作系统中的快捷方式
- 2.软链接可以 跨文件系统 ,硬链接不可以
- 3.软链接可以对一个不存在的文件名进行链接
- 4.软链接可以对目录进行链接
硬链接:
- 1.硬链接,以文件副本的形式存在。但不占用实际空间。
- 2.不允许给目录创建硬链接
- 3.硬链接只有在同一个文件系统中才能创建
参数说明
必要参数:
- –backup[=CONTROL] 备份已存在的目标文件
- -b 类似 –backup ,但不接受参数
- -d 允许超级用户制作目录的硬链接
- -f 强制执行
- -i 交互模式,文件存在则提示用户是否覆盖
- -n 把符号链接视为一般目录
- -s 软链接(符号链接)
- -v 显示详细的处理过程
选择参数:
- -S “-S<字尾备份字符串> “或 “–suffix=<字尾备份字符串>”
- -V “-V<备份方式>”或”–version-control=<备份方式>”
- –help 显示帮助信息
- –version 显示版本信息
实例
1 | 给文件创建软链接,为log2013.log文件创建软链接link2013,如果log2013.log丢失,link2013将失效: |
less
less命令可以随意浏览文件,支持翻页和搜索,支持向上翻页和向下翻页。
1 | 语法结构 |
参数说明
- -b <缓冲区大小> 设置缓冲区的大小
- -e 当文件显示结束后,自动离开
- -f 强迫打开特殊文件,例如外围设备代号、目录和二进制文件
- -g 只标志最后搜索的关键词
- -i 忽略搜索时的大小写
- -m 显示类似more命令的百分比
- -N 显示每行的行号
- -o <文件名> 将less 输出的内容在指定文件中保存起来
- -Q 不使用警告音
- -s 显示连续空行为一行
- -S 行过长时间将超出部分舍弃
- -x <数字> 将”tab”键显示为规定的数字空格
- /字符串:向下搜索”字符串”的功能
- ?字符串:向上搜索”字符串”的功能
- n:重复前一个搜索(与 / 或 ? 有关)
- N:反向重复前一个搜索(与 / 或 ? 有关)
- b 向上翻一页
- d 向后翻半页
- h 显示帮助界面
- Q 退出less 命令
- u 向前滚动半页
- y 向前滚动一行
- 空格键 滚动一页
- 回车键 滚动一行
- [pagedown]: 向下翻动一页
- [pageup]: 向上翻动一页
实例
1 | 查看文件 |
附加备注
1.全屏导航
- ctrl + F - 向前移动一屏
- ctrl + B - 向后移动一屏
- ctrl + D - 向前移动半屏
- ctrl + U - 向后移动半屏
2.单行导航
- j - 下一行
- k - 上一行
3.其它导航
- G - 移动到最后一行
- g - 移动到第一行
- q / ZZ - 退出 less 命令
4.其它有用的命令
- v - 使用配置的编辑器编辑当前文件
- h - 显示 less 的帮助文档
- &pattern - 仅显示匹配模式的行,而不是整个文件
5.标记导航
当使用 less 查看大文件时,可以在任何一个位置作标记,可以通过命令导航到标有特定标记的文本位置:
- ma - 使用 a 标记文本的当前位置
- ‘a - 导航到标记 a 处
locate
locate命令用于查找符合条件的文档,它会去保存文档和目录名称的数据库内,查找合乎范本样式条件的文档或目录。
一般情况我们只需要输入 locate your_file_name 即可查找指定文件。
1 | 语法格式 |
参数说明
- -b, –basename – 仅匹配路径名的基本名称
- -c, –count – 只输出找到的数量
- -d, –database DBPATH – 使用 DBPATH 指定的数据库,而不是默认数据库 /var/lib/mlocate/mlocate.db
- -e, –existing – 仅打印当前现有文件的条目
- -1 – 如果 是 1.则启动安全模式。在安全模式下,使用者不会看到权限无法看到 的档案。这会始速度减慢,因为 locate 必须至实际的档案系统中取得档案的 权限资料。
- -0, –null – 在输出上带有NUL的单独条目
- -S, –statistics – 不搜索条目,打印有关每个数据库的统计信息
- -q – 安静模式,不会显示任何错误讯息。
- -P, –nofollow, -H – 检查文件存在时不要遵循尾随的符号链接
- -l, –limit, -n LIMIT – 将输出(或计数)限制为LIMIT个条目
- -n – 至多显示 n个输出。
- -m, –mmap – 被忽略,为了向后兼容
- -r, –regexp REGEXP – 使用基本正则表达式
- –regex – 使用扩展正则表达式
- -q, –quiet – 安静模式,不会显示任何错误讯息
- -s, –stdio – 被忽略,为了向后兼容
- -o – 指定资料库存的名称。
- -h, –help – 显示帮助
- -i, –ignore-case – 忽略大小写
- -V, –version – 显示版本信息
实例
1 | 查找 passwd 文件,输入以下命令: |
附加说明
locate 与 find 不同: find 是去硬盘找,locate 只在 /var/lib/slocate 资料库中找。
locate 的速度比 find 快,它并不是真的查找,而是查数据库,一般文件数据库在 /var/lib/slocate/slocate.db 中,所以 locate 的查找并不是实时的,而是以数据库的更新为准,一般是系统自己维护,也可以手工升级数据库 ,命令为:
1 | updatedb #默认情况下 updatedb 每天执行一次。 |
lsattr
lsattr命令用于显示文件属性。
用chattr执行改变文件或目录的属性,可执行lsattr指令查询其属性。
1 | 语法结构 |
参数说明
- -a 显示所有文件和目录,包括以”.”为名称开头字符的额外内建,现行目录”.”与上层目录”..”。
- -d 显示,目录名称,而非其内容。
- -l 此参数目前没有任何作用。
- -R 递归处理,将指定目录下的所有文件及子目录一并处理。
- -v 显示文件或目录版本。
- -V 显示版本信息。
实例
1 | 用chattr命令防止系统中某个关键文件被修改: |
mattrib
mattrib命令用来变更或显示MS-DOS文件的属性。
mattrib为mtools工具指令,模拟MS-DOS的attrib指令,可变更MS-DOS文件的属性。
1 | 语法结构 |
参数说明
- -a/+a 除去/设定备份属性。
- -h/+h 除去/设定隐藏属性。
- -r/+r 除去/设定唯读属性。
- -s/+s 除去/设定系统属性。
- -/ 递回的处理包含所有子目录下的档案。
- -X 以较短的格式输出结果。
实例
1 | 列出 A 槽 MSDOS 格式磁片上所有文件的属性。 |
mc
mc命令用于提供一个菜单式的文件管理程序。执行mc之后,将会看到菜单式的文件管理程序,共分成4个部分。
1 | 语法结构 |
参数说明
- -a 当mc程序画线时不用绘图字符画线。
- -b 使用单色模式显示。
- -c 使用彩色模式显示。
- -C<参数> 指定显示的颜色。
- -d 不使用鼠标。
- -f 显示mc函数库所在的目录。
- -h 显示帮助。
- -k 重设softkeys成预设置。
- -l<文件> 在指定文件中保存ftpfs对话窗的内容。
- -P 程序结束时,列出最后的工作目录。
- -s 用慢速的终端机模式显示,在这模式下将减少大量的绘图及文字显示。
- -t 使用TEMPCAP变量设置终端机,而不使用预设置。
- -u 不用目前的shell程序。
- -U 使用目前的shell程序。
- -v<文件> 使用mc的内部编辑器来显示指定的文件。
- -V 显示版本信息。
- -x 指定以xterm模式显示。
相关操作
| 命令按键 | 描述 |
|---|---|
| F9 or Esc+9 | 激活菜单栏 |
| Tab | 在两个窗口间移动 |
| F10 or Esc+0 | 退出MC |
| Control-Enter or Alt-Enter | 可以将文件名拷贝到命令行 |
| F1 or Esc+1 | 打开帮助页面 |
mdel
mdel命令用来删除 MSDOS 格式的档案。在删除只读之前会有提示信息产生。
1 | 语法结构 |
参数说明
- -v 显示更多的讯息。
实例
1 | 将 A 槽磁片根目录中的 autoexec.bat 删除。 |
mdir
mdir命令用于显示MS-DOS目录。mdir为mtools工具指令,模拟MS-DOS的dir指令,可显示MS-DOS文件系统中的目录内容。
1 | 语法结构 |
参数说明
- -/ 显示目录下所有子目录与文件。
- -a 显示隐藏文件。
- -f 不显示磁盘所剩余的可用空间。
- -w 仅显示目录或文件名称,并以横排方式呈现,以便一次能显示较多的目录或文件。
- -X 仅显示目录下所有子目录与文件的完整路径,不显示其他信息。
实例
1 | 显示a盘中的内容 |
mktemp
mktemp命令用于建立暂存文件。mktemp建立的一个暂存文件,供shell script使用。
1 | 语法结构 |
参数说明
- -q 执行时若发生错误,不会显示任何信息。
- -u 暂存文件会在mktemp结束前先行删除。
- [文件名参数] 文件名参数必须是以”自订名称.XXXXXX”的格式。
实例
1 | 使用mktemp 命令生成临时文件时,文件名参数应当以"文件名.XXXX"的形式给出,mktemp 会根据文件名参数建立一个临时文件。在命令行提示符输入如下命令: |
由此可见,生成的临时文件为tmp.3847,其中,文件名参数中的”XXXX”被4 个随机产生的字符所取代。
more
more命令类似cat ,不过会以一页一页的形式显示,更方便使用者逐页阅读,而最基本的指令就是按空白键(space)就往下一页显示,按 b 键就会往回(back)一页显示,而且还有搜寻字串的功能(与 vi 相似),使用中的说明文件,请按 h 。
1 | 语法结构 |
参数说明
- -num 一次显示的行数
- -d 提示使用者,在画面下方显示 [Press space to continue, ‘q’ to quit.] ,如果使用者按错键,则会显示 [Press ‘h’ for instructions.] 而不是 ‘哔’ 声
- -l 取消遇见特殊字元 ^L(送纸字元)时会暂停的功能
- -f 计算行数时,以实际上的行数,而非自动换行过后的行数(有些单行字数太长的会被扩展为两行或两行以上)
- -p 不以卷动的方式显示每一页,而是先清除萤幕后再显示内容
- -c 跟 -p 相似,不同的是先显示内容再清除其他旧资料
- -s 当遇到有连续两行以上的空白行,就代换为一行的空白行
- -u 不显示下引号 (根据环境变数 TERM 指定的 terminal 而有所不同)
- +/pattern 在每个文档显示前搜寻该字串(pattern),然后从该字串之后开始显示
- +num 从第 num 行开始显示
- fileNames 欲显示内容的文档,可为复数个数
实例
1 | 逐页显示 testfile 文档内容,如有连续两行以上空白行则以一行空白行显示。 |
常用操作命令
- Enter 向下n行,需要定义。默认为1行
- Ctrl+F 向下滚动一屏
- 空格键 向下滚动一屏
- Ctrl+B 返回上一屏
- = 输出当前行的行号
- :f 输出文件名和当前行的行号
- V 调用vi编辑器
- !命令 调用Shell,并执行命令
- q 退出more
mmove
mmove命令用于在MS-DOS文件系统中,移动文件或目录,或更改名称。
mmove为mtools工具命令,模拟MS-DOS的move命令,可在MS-DOS文件系统中移动现有的文件或目录,或是更改现有文件或目录的名称。
1 | 语法结构 |
参数说明
实例
1 | 使用指令mmove将文件"autorun.bat"移动到目录"test"中,输入如下命令: |
以上命令执行以后,指令mmove会将文件”autorun.bat”移动到指定目录”test”中。
注意:用户可以使用mdir指令查看移动后的文件或目录信息。
mread
mread命令用于将MS-DOS文件复制到Linux/Unix的目录中。
mread为mtools工具命令,可将MS-DOS文件复制到Linux的文件系统中。这个命令目前已经不常用,一般都使用mcopy命令来代替。
1 | 语法结构 |
参数说明
实例
1 | 使用指令mread将盘"a:\"中的所有内容复制到当前工作目录下,输入如下命令: |
mren
mren命令用于更改MS-DOS文件或目录的名称,或是移动文件或目录。
mren为MS-DOS工具指令,与DOS下的ren指令相似,可以实现更改MS-DOS文件或目录名称。
源文件必须是磁盘上已经存在的文件,若忽略盘符及路径,则表示当前盘及当前目录的文件。
新文件名是所要更换的文件名称。新文件名称前不可以加与源文件不同的盘符及路径,因为该命令只能更改同一盘上的文件名称。
1 | 语法结构 |
参数说明
实例
1 | 使用指令mren将a盘下的文件"autorun.bat"的文件名修改为"auto.bat",输入如下命令: |
mtools
mtools命令用于显示mtools支持的指令。
mtools为MS-DOS文件系统的工具程序,可模拟许多MS-DOS的指令。这些指令都是mtools的符号连接,因此会有一些共同的特性。
1 | 语法结构 |
参数说明
- -a 长文件名重复时自动更改目标文件的长文件名。
- -A 短文件名重复但长文件名不同时自动更改目标文件的短文件名。
- -o 长文件名重复时,将目标文件覆盖现有的文件。
- -O 短文件名重复但长文件名不同时,将目标文件覆盖现有的文件。
- -r 长文件名重复时,要求用户更改目标文件的长文件名。
- -R 短文件名重复但长文件名不同时,要求用户更改目标文件的短文件名。
- -s 长文件名重复时,则不处理该目标文件。
- -S 短文件名重复但长文件名不同时,则不处理该目标文件。
- -v 执行时显示详细的说明。
- -V 显示版本信息。
实例
1 | 显示 mtools软件包所支持的MS-DOS命令。 |
mtoolstest
mtoolstest命令用于测试并显示mtools的相关设置。
mtoolstest为mtools工具指令,可读取与分析mtools的配置文件,并在屏幕上显示结果。
1 | 语法结构 |
实例
1 | 在命令行中直接输入mtoolstest,即可显示mtools软件包当前的配置信息,结果如下: |
mv
mv命令用来为文件或目录改名、或将文件或目录移入其它位置。
1 | 语法结构 |
参数说明
- -b: 当目标文件或目录存在时,在执行覆盖前,会为其创建一个备份。
- -i: 如果指定移动的源目录或文件与目标的目录或文件同名,则会先询问是否覆盖旧文件,输入 y 表示直接覆盖,输入 n 表示取消该操作。
- -f: 如果指定移动的源目录或文件与目标的目录或文件同名,不会询问,直接覆盖旧文件。
- -n: 不要覆盖任何已存在的文件或目录。
- -u:当源文件比目标文件新或者目标文件不存在时,才执行移动操作。
mv参数设置与运行结果
| 命令格式 | 运行结果 |
|---|---|
| mv source_file(文件) dest_file(文件) | 将源文件名 source_file 改为目标文件名 dest_file |
| mv source_file(文件) dest_directory(目录) | 将文件 source_file 移动到目标目录 dest_directory 中 |
| mv source_directory(目录) dest_directory(目录) | 目录名 dest_directory 已存在,将 source_directory 移动到目录名 dest_directory 中;目录名 dest_directory 不存在则 source_directory 改名为目录名 dest_directory |
| mv source_directory(目录) dest_file(文件) | 出错 |
实例
1 | 将文件 aaa 改名为 bbb : |
od
od命令用于输出文件内容。od指令会读取所给予的文件的内容,并将其内容以八进制字码呈现出来。
1 | 语法结构 |
参数说明
- -a 此参数的效果和同时指定”-ta”参数相同。
- -A<字码基数> 选择要以何种基数计算字码。
- -b 此参数的效果和同时指定”-toC”参数相同。
- -c 此参数的效果和同时指定”-tC”参数相同。
- -d 此参数的效果和同时指定”-tu2”参数相同。
- -f 此参数的效果和同时指定”-tfF”参数相同。
- -h 此参数的效果和同时指定”-tx2”参数相同。
- -i 此参数的效果和同时指定”-td2”参数相同。
- -j<字符数目>或–skip-bytes=<字符数目> 略过设置的字符数目。
- -l 此参数的效果和同时指定”-td4”参数相同。
- -N<字符数目>或–read-bytes=<字符数目> 到设置的字符数目为止。
- -o 此参数的效果和同时指定”-to2”参数相同。
- -s<字符串字符数>或–strings=<字符串字符数> 只显示符合指定的字符数目的字符串。
- -t<输出格式>或–format=<输出格式> 设置输出格式。
- -v或–output-duplicates 输出时不省略重复的数据。
- -w<每列字符数>或–width=<每列字符数> 设置每列的最大字符数。
- -x 此参数的效果和同时指定”-h”参数相同。
- –help 在线帮助。
- –version 显示版本信息。
实例
1 | 创建 tmp 文件: |
paste
paste 命令用于合并文件的列。
1 | 语法结构 |
说明参数
- -d<间隔字符>或–delimiters=<间隔字符> 用指定的间隔字符取代跳格字符。
- -s或–serial 串列进行而非平行处理。
- –help 在线帮助。
- –version 显示帮助信息。
- [文件…] 指定操作的文件路径
实例
1 | 使用paste指令将文件"file"、"testfile"、"testfile1"进行合并,输入如下命令: |
注意:参数”-s”只是将testfile文件的内容调整显示方式,并不会改变原文件的内容格式。
patch
patch命令用于修补文件。
patch指令让用户利用设置修补文件的方式,修改,更新原始文件。倘若一次仅修改一个文件,可直接在指令列中下达指令依序执行。如果配合修补文件的方式则能一次修补大批文件,这也是Linux系统核心的升级方法之一。
1 | 语法结构 |
说明参数
- -b或–backup 备份每一个原始文件。
- -B<备份字首字符串>或–prefix=<备份字首字符串> 设置文件备份时,附加在文件名称前面的字首字符串,该字符串可以是路径名称。
- -c或–context 把修补数据解译成关联性的差异。
- -d<工作目录>或–directory=<工作目录> 设置工作目录。
- -D<标示符号>或–ifdef=<标示符号> 用指定的符号把改变的地方标示出来。
- -e或–ed 把修补数据解译成ed指令可用的叙述文件。
- -E或–remove-empty-files 若修补过后输出的文件其内容是一片空白,则移除该文件。
- -f或–force 此参数的效果和指定”-t”参数类似,但会假设修补数据的版本为新 版本。
- -F<监别列数>或–fuzz<监别列数> 设置监别列数的最大值。
- -g<控制数值>或–get=<控制数值> 设置以RSC或SCCS控制修补作业。
- -i<修补文件>或–input=<修补文件> 读取指定的修补文件。
- -l或–ignore-whitespace 忽略修补数据与输入数据的跳格,空格字符。
- -n或–normal 把修补数据解译成一般性的差异。
- -N或–forward 忽略修补的数据较原始文件的版本更旧,或该版本的修补数据已使 用过。
- -o<输出文件>或–output=<输出文件> 设置输出文件的名称,修补过的文件会以该名称存放。
- -p<剥离层级>或–strip=<剥离层级> 设置欲剥离几层路径名称。
- -f<拒绝文件>或–reject-file=<拒绝文件> 设置保存拒绝修补相关信息的文件名称,预设的文件名称为.rej。
- -R或–reverse 假设修补数据是由新旧文件交换位置而产生。
- -s或–quiet或–silent 不显示指令执行过程,除非发生错误。
- -t或–batch 自动略过错误,不询问任何问题。
- -T或–set-time 此参数的效果和指定”-Z”参数类似,但以本地时间为主。
- -u或–unified 把修补数据解译成一致化的差异。
- -v或–version 显示版本信息。
- -V<备份方式>或–version-control=<备份方式> 用”-b”参数备份目标文件后,备份文件的字尾会被加上一个备份字符串,这个字符串不仅可用”-z”参数变更,当使用”-V”参数指定不同备份方式时,也会产生不同字尾的备份字符串。
- -Y<备份字首字符串>或–basename-prefix=–<备份字首字符串> 设置文件备份时,附加在文件基本名称开头的字首字符串。
- -z<备份字尾字符串>或–suffix=<备份字尾字符串> 此参数的效果和指定”-B”参数类似,差别在于修补作业使用的路径与文件名若为src/linux/fs/super.c,加上”backup/“字符串后,文件super.c会备份于/src/linux/fs/backup目录里。
- -Z或–set-utc 把修补过的文件更改,存取时间设为UTC。
- –backup-if-mismatch 在修补数据不完全吻合,且没有刻意指定要备份文件时,才备份文件。
- –binary 以二进制模式读写数据,而不通过标准输出设备。
- –help 在线帮助。
- –nobackup-if-mismatch 在修补数据不完全吻合,且没有刻意指定要备份文件时,不要备份文件。
- –verbose 详细显示指令的执行过程。
实例
1 | 使用patch指令将文件"testfile1"升级,其升级补丁文件为"testfile.patch",输入如下命令: |
注意:上述命令代码中,”$ diff testfile1 testfile2>testfile. patch”所使用的操作符”>”表示将该操作符左边的文件数据写入到右边所指向的文件中。在这里,即是指将两个文件比较后的结果写入到文件”testfile.patch”中。
rcp
rcp命令用于复制远程文件或目录。
rcp指令用在远端复制文件或目录,如同时指定两个以上的文件或目录,且最后的目的地是一个已经存在的目录,则它会把前面指定的所有文件或目录复制到该目录中。
1 | 语法结构 |
说明参数
-p 保留源文件或目录的属性,包括拥有者,所属群组,权限与时间。
-r 递归处理,将指定目录下的文件与子目录一并处理。
实例
1 | 使用rcp指令复制远程文件到本地进行保存。 |
注意:指令”rcp”执行以后不会有返回信息,仅需要在目录”test”下查看是否存在文件”testfile”。若存在,则表示远程复制操作成功,否则远程复制操作失败。
rm
rm命令用于删除一个文件或者目录。
1 | 语法结构 |
说明参数
- -i 删除前逐一询问确认。
- -f 即使原档案属性设为唯读,亦直接删除,无需逐一确认。
- -r 将目录及以下之档案亦逐一删除。
实例
1 | 删除文件可以直接使用rm命令,若删除目录则必须配合选项"-r",例如: |
文件一旦通过rm命令删除,则无法恢复,所以必须格外小心地使用该命令。
slocate
slocate命令查找文件或目录。
slocate本身具有一个数据库,里面存放了系统中文件与目录的相关信息。
1 | 语法结构 |
说明参数
- -d<目录>或–database=<目录> 指定数据库所在的目录。
- -u 更新slocate数据库。
- –help 显示帮助。
- –version 显示版本信息。
实例
1 | 使用指令"slocate"显示文件名中含有关键字"fdisk"的文件路径信息,输入如下命令: |
split
split命令用于将一个文件分割成数个。该指令将大文件分割成较小的文件,在默认情况下将按照每1000行切割成一个小文件。
1 | 语法结构 |
参数说明
- -<行数> : 指定每多少行切成一个小文件
- -b<字节> : 指定每多少字节切成一个小文件
- –help : 在线帮助
- –version : 显示版本信息
- -C<字节> : 与参数”-b”相似,但是在切 割时将尽量维持每行的完整性
- [输出文件名] : 设置切割后文件的前置文件名, split会自动在前置文件名后再加上编号
实例
1 | 使用指令"split"将文件"README"每6行切割成一个文件,输入如下命令: |
tee
tee命令用于读取标准输入的数据,并将其内容输出成文件。
tee指令会从标准输入设备读取数据,将其内容输出到标准输出设备,同时保存成文件。
1 | 语法结构 |
说明参数
- -a或–append 附加到既有文件的后面,而非覆盖它.
- -i或–ignore-interrupts 忽略中断信号。
- –help 在线帮助。
- –version 显示版本信息。
实例
1 | 使用指令"tee"将用户输入的数据同时保存到文件"file1"和"file2"中,输入如下命令: |
此时,可以分别打开文件”file1”和”file2”,查看其内容是否均是”My Linux”即可判断指令”tee”是否执行成功。
tempwatch
tmpwatch命令用于删除暂存文件。
执行tmpwatch指令可删除不必要的暂存文件,您可以设置文件超期时间,单位以小时计算。
1 | 语法结构 |
说明参数
- -a或–all 删除任何类型的文件。
- -f或–force 强制删除文件或目录,其效果类似rm指令的”-f”参数。
- -q或–quiet 不显示指令执行过程。
- -v或–verbose 详细显示指令执行过程。
- -test 仅作测试,并不真的删除文件或目录。
实例
1 | 使用指令"tmpwatch"删除目录"/tmp"中超过一天未使用的文件,输入如下命令: |
touch
touch命令用于修改文件或者目录的时间属性,包括存取时间和更改时间。若文件不存在,系统会建立一个新的文件。
ls -l 可以显示档案的时间记录。
1 | 语法结构 |
参数说明
- a 改变档案的读取时间记录。
- m 改变档案的修改时间记录。
- c 假如目的档案不存在,不会建立新的档案。与 –no-create 的效果一样。
- f 不使用,是为了与其他 unix 系统的相容性而保留。
- r 使用参考档的时间记录,与 –file 的效果一样。
- d 设定时间与日期,可以使用各种不同的格式。
- t 设定档案的时间记录,格式与 date 指令相同。
- –no-create 不会建立新档案。
- –help 列出指令格式。
- –version 列出版本讯息。
实例
1 | 使用指令"touch"修改文件"testfile"的时间属性为当前系统时间,输入如下命令: |
umask
umask命令指定在建立文件时预设的权限掩码。
umask可用来设定[权限掩码]。[权限掩码]是由3个八进制的数字所组成,将现有的存取权限减掉权限掩码后,即可产生建立文件时预设的权限。
1 | 语法结构 |
参数说明
-S 以文字的方式来表示权限掩码。
实例
1 | 使用指令"umask"查看当前权限掩码,则输入下面的命令: |
注意:在上面的输出信息中,”drwxr-xr-x”=”777-022=755”。
which
which命令用于查找文件。
which指令会在环境变量$PATH设置的目录里查找符合条件的文件。
1 | 语法结构 |
说明参数
- -n<文件名长度> 指定文件名长度,指定的长度必须大于或等于所有文件中最长的文件名。
- -p<文件名长度> 与-n参数相同,但此处的<文件名长度>包括了文件的路径。
- -w 指定输出时栏位的宽度。
- -V 显示版本信息。
实例
1 | 使用指令"which"查看指令"bash"的绝对路径,输入如下命令: |
cp
cp命令主要用于复制文件或目录。
1 | 语法结构 |
参数说明
- -a:此选项通常在复制目录时使用,它保留链接、文件属性,并复制目录下的所有内容。其作用等于dpR参数组合。
- -d:复制时保留链接。这里所说的链接相当于 Windows 系统中的快捷方式。
- -f:覆盖已经存在的目标文件而不给出提示。
- -i:与 -f 选项相反,在覆盖目标文件之前给出提示,要求用户确认是否覆盖,回答 y 时目标文件将被覆盖。
- -p:除复制文件的内容外,还把修改时间和访问权限也复制到新文件中。
- -r:若给出的源文件是一个目录文件,此时将复制该目录下所有的子目录和文件。
- -l:不复制文件,只是生成链接文件。
实例
1 | 使用指令 cp 将当前目录 test/ 下的所有文件复制到新目录 newtest 下,输入如下命令: |
注意:用户使用该指令复制目录时,必须使用参数 -r 或者 -R 。
whereis
whereis命令用于查找文件。
该指令会在特定目录中查找符合条件的文件。这些文件应属于原始代码、二进制文件,或是帮助文件。
该指令只能用于查找二进制文件、源代码文件和man手册页,一般文件的定位需使用locate命令。
1 | 语法结构 |
说明参数
-b 只查找二进制文件。
-B<目录> 只在设置的目录下查找二进制文件。
-f 不显示文件名前的路径名称。
-m 只查找说明文件。
-M<目录> 只在设置的目录下查找说明文件。
-s 只查找原始代码文件。
-S<目录> 只在设置的目录下查找原始代码文件。
-u 查找不包含指定类型的文件。
实例
1 | 使用指令"whereis"查看指令"bash"的位置,输入如下命令: |
mcopy
mcopy命令用来复制 MSDOS 格式文件到 Linux 中,或是由 Linux 中复制 MSDOS 文件到磁片上。
mcopy 可复制单一的文件到所指定的文件名称,或是复制数个文件到所指定的目录之中。来源与目的文件可为 MSDOS 或是 Linux 文件。
mcopy指令是一种mtools工具指令,可以在DOS系统中复制文件或者在DOS与Linux操作系统之间进行文件复制。
1 | 语法结构 |
说明参数
- b 批处理模式。这是为大量的文件复制进行最佳化的选项,但是当在复制文件过程中产生 crash 时,会有安全性的问题产生。/ 递回的复制。包含目录所含文件与其下所有子目录中的文件。
- -n 覆盖其他文件时,不需要进行确认而直接覆盖
- m 将源文件修改时间设置为目标文件的修改时间。
- p 将源文件的属性设置为目标文件的属性。
- Q 当复制多个文件产生错误时,尽快结束程序。
- t 转换为文本文件。
- o 在覆盖 MSDOS 文件时不会出现警示讯息。
实例
1 | 将 A 盘根目录中的 autoexec.bat 复制到目前工作目录之下: |
mshowfat
mshowfat命令用于显示MS-DOS文件在FAT中的记录。
mshowfat为mtools工具指令,可显示MS-DOS文件在FAT中的记录编号。
1 | 语法结构 |
参数说明
[文件…]: 执行操作的文件相对路径或者绝对路径
实例
1 | 使用指令mshowfat查看文件"autorun.bat"的FAT信息,输入如下命令: |
以上命令执行后,文件”autorun.bat”的FAT相关信息将会被显示出来。
注意:执行操作的文件必须是DOS文件系统下的文件。
rhmask
rhmask命令用于对文件进行加密和解密操作。
执行rhmask指令可制作加密过的文件,方便用户在公开的网络上传输该文件,而不至于被任意盗用。
1 | 语法结构 |
说明参数
- -d 产生加密过的文件。
实例
1 | 使用指令"rhmask"将加密文件"code.txt"进行加密后,另存为输出文件"demo.txt",输入如下命令: |
以上命令执行后,文件”code.txt”将被加密后,另存为已经加密的文件”demo.txt”。
注意:该指令有两种语法,用户可以有选择性地进行使用即可。
scp
scp 命令用于 Linux 之间复制文件和目录。
scp 是 secure copy 的缩写, scp 是 linux 系统下基于 ssh 登陆进行安全的远程文件拷贝命令。
scp 是加密的,rcp 是不加密的,scp 是 rcp 的加强版。
1 | 语法结构 |
参数说明
- -1: 强制scp命令使用协议ssh1
- -2: 强制scp命令使用协议ssh2
- -4: 强制scp命令只使用IPv4寻址
- -6: 强制scp命令只使用IPv6寻址
- -B: 使用批处理模式(传输过程中不询问传输口令或短语)
- -C: 允许压缩。(将-C标志传递给ssh,从而打开压缩功能)
- -p:保留原文件的修改时间,访问时间和访问权限。
- -q: 不显示传输进度条。
- -r: 递归复制整个目录。
- -v:详细方式显示输出。scp和ssh(1)会显示出整个过程的调试信息。这些信息用于调试连接,验证和配置问题。
- -c cipher: 以cipher将数据传输进行加密,这个选项将直接传递给ssh。
- -F ssh_config: 指定一个替代的ssh配置文件,此参数直接传递给ssh。
- -i identity_file: 从指定文件中读取传输时使用的密钥文件,此参数直接传递给ssh。
- -l limit: 限定用户所能使用的带宽,以Kbit/s为单位。
- -o ssh_option: 如果习惯于使用ssh_config(5)中的参数传递方式,
- -P port:注意是大写的P, port是指定数据传输用到的端口号
- -S program: 指定加密传输时所使用的程序。此程序必须能够理解ssh(1)的选项。
实例
1 | 从本地复制到远程 |
- 第1,2个指定了用户名,命令执行后需要再输入密码,第1个仅指定了远程的目录,文件名字不变,第2个指定了文件名;
- 第3,4个没有指定用户名,命令执行后需要输入用户名和密码,第3个仅指定了远程的目录,文件名字不变,第4个指定了文件名;
1 | 复制目录命令格式: |
- 第1个指定了用户名,命令执行后需要再输入密码;
- 第2个没有指定用户名,命令执行后需要输入用户名和密码;
1 | 从远程复制到本地 |
说明
如果远程服务器防火墙有为scp命令设置了指定的端口,我们需要使用 -P 参数来设置命令的端口号,命令格式如下:
1
2scp 命令使用端口号 4588
scp -P 4588 remote@www.runoob.com:/usr/local/sin.sh /home/administrator使用scp命令要确保使用的用户具有可读取远程服务器相应文件的权限,否则scp命令是无法起作用的。
awk
awk 是一种处理文本文件的语言,是一个强大的文本分析工具。
之所以叫 AWK 是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符。
1 | 语法结构 |
参数说明
- -F fs or –field-separator fs
指定输入文件折分隔符,fs是一个字符串或者是一个正则表达式,如-F:。 - -v var=value or –asign var=value
赋值一个用户定义变量。 - -f scripfile or –file scriptfile
从脚本文件中读取awk命令。 - -mf nnn and -mr nnn
对nnn值设置内在限制,-mf选项限制分配给nnn的最大块数目;-mr选项限制记录的最大数目。这两个功能是Bell实验室版awk的扩展功能,在标准awk中不适用。 - -W compact or –compat, -W traditional or –traditional
在兼容模式下运行awk。所以gawk的行为和标准的awk完全一样,所有的awk扩展都被忽略。 - -W copyleft or –copyleft, -W copyright or –copyright
打印简短的版权信息。 - -W help or –help, -W usage or –usage
打印全部awk选项和每个选项的简短说明。 - -W lint or –lint
打印不能向传统unix平台移植的结构的警告。 - -W lint-old or –lint-old
打印关于不能向传统unix平台移植的结构的警告。 - -W posix
打开兼容模式。但有以下限制,不识别:/x、函数关键字、func、换码序列以及当fs是一个空格时,将新行作为一个域分隔符;操作符和=不能代替^和^=;fflush无效。 - -W re-interval or –re-inerval
允许间隔正则表达式的使用,参考(grep中的Posix字符类),如括号表达式[[:alpha:]]。 - -W source program-text or –source program-text
使用program-text作为源代码,可与-f命令混用。 - -W version or –version
打印bug报告信息的版本。
基本用法
log.txt文本内容如下:
1 | 2 this is a test |
用法一
1 | awk '{[pattern] action}' {filenames} # 行匹配语句 awk '' 只能用单引号 |
用法二
1 | awk -F #-F相当于内置变量FS, 指定分割字符 |
用法三
1 | awk -v # 设置变量 |
用法四
1 | awk -f {awk脚本} {文件名} |
运算符
| 运算符 | 描述 |
|---|---|
| = += -= *= /= %= ^= **= | 赋值 |
| ?: | C条件表达式 |
| || | 逻辑或 |
| && | 逻辑与 |
| ~ 和 !~ | 匹配正则表达式和不匹配正则表达式 |
| < <= > >= != | 关系运算符 |
| 空格 | 连接 |
| + - | 加,减 |
| * / % | 乘,除与求余 |
| + - ! | 一元加,减和逻辑非 |
| ^ *** | 求幂 |
| ++ – | 增加或减少,作为前缀或后缀 |
| $ | 字段引用 |
| in | 数组成员 |
1 | 过滤第一列大于2的行 |
内建变量
| 变量 | 描述 |
|---|---|
| $n | 当前记录的第n个字段,字段间由FS分隔 |
| $0 | 完整的输入记录 |
| ARGC | 命令行参数的数目 |
| ARGIND | 命令行中当前文件的位置(从0开始算) |
| ARGV | 包含命令行参数的数组 |
| CONVFMT | 数字转换格式(默认值为%.6g)ENVIRON环境变量关联数组 |
| ERRNO | 最后一个系统错误的描述 |
| FIELDWIDTHS | 字段宽度列表(用空格键分隔) |
| FILENAME | 当前文件名 |
| FNR | 各文件分别计数的行号 |
| FS | 字段分隔符(默认是任何空格) |
| IGNORECASE | 如果为真,则进行忽略大小写的匹配 |
| NF | 一条记录的字段的数目 |
| NR | 已经读出的记录数,就是行号,从1开始 |
| OFMT | 数字的输出格式(默认值是%.6g) |
| OFS | 输出字段分隔符,默认值与输入字段分隔符一致。 |
| ORS | 输出记录分隔符(默认值是一个换行符) |
| RLENGTH | 由match函数所匹配的字符串的长度 |
| RS | 记录分隔符(默认是一个换行符) |
| RSTART | 由match函数所匹配的字符串的第一个位置 |
| SUBSEP | 数组下标分隔符(默认值是/034) |
1 | awk 'BEGIN{printf "%4s %4s %4s %4s %4s %4s %4s %4s %4s\n","FILENAME","ARGC","FNR","FS","NF","NR","OFS","ORS","RS";printf "---------------------------------------------\n"} {printf "%4s %4s %4s %4s %4s %4s %4s %4s %4s\n",FILENAME,ARGC,FNR,FS,NF,NR,OFS,ORS,RS}' log.txt |
使用正则,字符串匹配
1 | 输出第二列包含 "th",并打印第二列与第四列 |
忽略大小写
1 | awk 'BEGIN{IGNORECASE=1} /this/' log.txt |
模式取反
1 | awk '$2 !~ /th/ {print $2,$4}' log.txt |
awk脚本
关于 awk 脚本,我们需要注意两个关键词 BEGIN 和 END。
- BEGIN{ 这里面放的是执行前的语句 }
- END {这里面放的是处理完所有的行后要执行的语句 }
- {这里面放的是处理每一行时要执行的语句}
假设有这么一个文件(学生成绩表):
1 | cat score.txt |
awk脚本如下
1 | cat cal.awk |
1 | 执行结果 |
其他实例
1 | AWK 的 hello world 程序为: |
read
read命令用于从标准输入读取数值。
read 内部命令被用来从标准输入读取单行数据。这个命令可以用来读取键盘输入,当使用重定向的时候,可以读取文件中的一行数据。
1 | 语法结构 |
参数说明
- -a 后跟一个变量,该变量会被认为是个数组,然后给其赋值,默认是以空格为分割符。
- -d 后面跟一个标志符,其实只有其后的第一个字符有用,作为结束的标志。
- -p 后面跟提示信息,即在输入前打印提示信息。
- -e 在输入的时候可以使用命令补全功能。
- -n 后跟一个数字,定义输入文本的长度,很实用。
- -r 屏蔽\,如果没有该选项,则\作为一个转义字符,有的话 \就是个正常的字符了。
- -s 安静模式,在输入字符时不再屏幕上显示,例如login时输入密码。
- -t 后面跟秒数,定义输入字符的等待时间。
- -u 后面跟fd,从文件描述符中读入,该文件描述符可以是exec新开启的。
实例
1 | 简单读取 |
1 | 只接收 2 个输入就退出: |
updatedb
命令用来创建或更新 slocate/locate 命令所必需的数据库文件。
pdatedb 命令的执行过程较长,因为在执行时它会遍历整个系统的目录树,并将所有的文件信息写入 slocate/locate 数据库文件中。
**注意:**slocate 本身具有一个数据库,里面存放了系统中文件与目录的相关信息。
1 | 语法结构 |
参数说明
- -o<文件>:忽略默认的数据库文件,使用指定的slocate数据库文件;
- -U<目录>:更新指定目录的slocate数据库;
- -v:显示执行的详细过程。
实例
1 | 检测一个未存在的文件 runoob.txt: |
文档编辑
col
col命令用于过滤控制字符。在许多UNIX说明文件里,都有RLF控制字符。当我们运用shell特殊字符”>”和”>>”,把说明文件的内容输出成纯文本文件时,控制字符会变成乱码,col指令则能有效滤除这些控制字符。
1 | 语法结构 |
参数说明
- -b 过滤掉所有的控制字符,包括RLF和HRLF。
- -f 滤除RLF字符,但允许将HRLF字符呈现出来。
- -x 以多个空格字符来表示跳格字符。
- -l<缓冲区列数> 预设的内存缓冲区有128列,您可以自行指定缓冲区的大小。
实例
1 | 下面以 man 命令帮助文档为例,讲解col 命令的使用。 |
**注:**其中”|”用于建立管道,把man命令的输出结果转为col命令的输入数据。
colrm
colrm命令用于滤掉指定的行。
colrm指令从标准输入设备读取数据,转而输出到标准输出设备。如果不加任何参数,则该指令不会过滤任何一行。
1 | 语法结构 |
参数说明
- 开始行数编号: 指定要删除的列的起始编号。
- 结束行数编号: 指定要删除的列的结束编号,有时候这个参数可以省略。
实例
1 | 不带任何参数时该命令不会删除任何列: |
comm
comm命令用于比较两个已排过序的文件。
这项指令会一列列地比较两个已排序文件的差异,并将其结果显示出来,如果没有指定任何参数,则会把结果分成 3 列显示:第 1 列仅是在第 1 个文件中出现过的列,第 2 列是仅在第 2 个文件中出现过的列,第 3 列则是在第 1 与第 2 个文件里都出现过的列。若给予的文件名称为 - ,则 comm 指令会从标准输入设备读取数据。
1 | 语法结构 |
参数说明
- -1 不显示只在第 1 个文件里出现过的列。
- -2 不显示只在第 2 个文件里出现过的列。
- -3 不显示只在第 1 和第 2 个文件里出现过的列。
- –help 在线帮助。
- –version 显示版本信息。
实例
1 | aaa.txt 与 bbb.txt 的文件内容如下: |
输出的第一列只包含在 aaa.txt 中出现的列,第二列包含在 bbb.txt 中出现的列,第三列包含在 aaa.txt 和 bbb.txt 中都包含的列。各列是以制表符 \t 作为定界符。
csplit
csplit命令用于分割文件。
将文件依照指定的范本样式予以切割后,分别保存成名称为xx00,xx01,xx02…的文件。若给予的文件名称为”-“,则csplit指令会从标准输入设备读取数据。
1 | 语法结构 |
参数说明
- -b<输出格式>或–suffix-format=<输出格式> 预设的输出格式其文件名称为xx00,xx01…等,您可以通过改变<输出格式>来改变输出的文件名。
- -f<输出字首字符串>或–prefix=<输出字首字符串> 预设的输出字首字符串其文件名为xx00,xx01…等,如果你指定输出字首字符串为”hello”,则输出的文件名称会变成hello00,hello01…等。
- -k或–keep-files 保留文件,就算发生错误或中断执行,也不能删除已经输出保存的文件。
- -n<输出文件名位数>或–digits=<输出文件名位数> 预设的输出文件名位数其文件名称为xx00,xx01…等,如果你指定输出文件名位数为”3”,则输出的文件名称会变成xx000,xx001…等。
- -q或-s或–quiet或–silent 不显示指令执行过程。
- -z或–elide-empty-files 删除长度为0 Byte文件。
- –help 在线帮助。
- –version 显示版本信息。
实例
1 | 将文本文件testfile以第 2 行为分界点切割成两份,使用如下命令: |
ed
ed命令是文本编辑器,用于文本编辑。
ed是Linux中功能最简单的文本编辑程序,一次仅能编辑一行而非全屏幕方式的操作。
ed命令并不是一个常用的命令,一般使用比较多的是vi 指令。但ed文本编辑器对于编辑大文件或对于在shell脚本程序中进行文本编辑很有用。
1 | 语法结构 |
参数说明
- -G或–traditional 提供回兼容的功能。
- -p<字符串> 指定ed在command mode的提示字符。
- -s,-,–quiet或–silent 不执行开启文件时的检查功能。
- –help 显示帮助。
- –version 显示版本信息。
实例
1 | Linux ed 完整实例解析: |
egrep
egrep命令用于在文件内查找指定的字符串。
egrep执行效果与”grep-E”相似,使用的语法及参数可参照grep指令,与grep的不同点在于解读字符串的方法。
egrep是用extended regular expression语法来解读的,而grep则用basic regular expression 语法解读,extended regular expression比basic regular expression的表达更规范。
1 | 语法结构 |
参数说明
- [范本模式] :查找的字符串规则。
- [文件或目录] :查找的目标文件或目录。
实例
1 | 显示文件中符合条件的字符。例如,查找当前目录下所有文件中包含字符串"Linux"的文件,可以使用如下命令: |
ex
ex命令用于在Ex模式下启动vim文本编辑器。
ex执行效果如同vi -E,使用语法及参数可参照vi指令,如要从Ex模式回到普通模式,则在vim中输入”:vi”或”:visual”指令即可。
1 | 语法结构 |
参数说明
- +数字:从文件指定的数字行开始显示
- -b:使用二进制模式编辑文件
- -c 指令:编辑完第一个文件后执行指定的指令
- -d :编辑多个文件时,显示差异部分
- -m :不允许修改文件
- -n :不使用缓存
- -oN:其中 N 为数字
- -r :列出缓存,并显示恢复信息
- -R :以只读的方式打开文件
- -s :不显示任何错误信息
- -V :显示指令的详细执行过程
- –help :显示帮助信息
- –version :显示版本信息
实例
1 | 在ex 指令后输入文件名按回车键后,即可进入ex 编辑模式,如编辑testfile文件,使用的命令格式如下: |
“testfile”表示文件名,5L表示5 行,95 表示字节数
进入ex 模式。输入”visual”回到正常模式
它的操作与vim 中是一样的,此时如果在”:”后输入”visual”后按回车键,将进入到vi 指令全屏界面;如果输入”q”,则退出编辑器。
fgrep
fgrep命令相当于执行 grep 指令加上参数 -F,用于查找文件里符合条件的字符串。
1 | 语法结构 |
fmt
fmt命令用于编排文本文件。
fmt指令会从指定的文件里读取内容,将其依照指定格式重新编排后,输出到标准输出设备。若指定的文件名为”-“,则fmt指令会从标准输入设备读取数据
1 | 语法结构 |
参数说明
- -c或–crown-margin 每段前两列缩排。
- -p<列起始字符串>或-prefix=<列起始字符串> 仅合并含有指定字符串的列,通常运用在程序语言的注解方面。
- -s或–split-only 只拆开字数超出每列字符数的列,但不合并字数不足每列字符数的列。
- -t或–tagged-paragraph 每列前两列缩排,但第1列和第2列的缩排格式不同。
- -u或–uniform-spacing 每个字符之间都以一个空格字符间隔,每个句子之间则两个空格字符分隔。
- -w<每列字符数>或–width=<每列字符数>或-<每列字符数> 设置每列的最大字符数。
- –help 在线帮助。
- –version 显示版本信息。
实例
1 | 重排指定文件。如文件testfile共5 行文字,可以通过命令对该文件格式进行重排,其命令为: |
fold
fold命令用于限制文件列宽。
fold指令会从指定的文件里读取内容,将超过限定列宽的列加入增列字符后,输出到标准输出设备。若不指定任何文件名称,或是所给予的文件名为”-“,则fold指令会从标准输入设备读取数据。
1 | 语法结构 |
参数说明
- -b或–bytes 以Byte为单位计算列宽,而非采用行数编号为单位。
- -s或–spaces 以空格字符作为换列点。
- -w<每列行数>或–width<每列行数> 设置每列的最大行数。
- –help 在线帮助。
- –version 显示版本信息。
实例
1 | 将一个名为testfile 的文件的行折叠成宽度为30,可使用如下命令: |
grep
grep命令用于查找文件里符合条件的字符串或正则表达式。
grep 指令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设 grep 指令会把含有范本样式的那一列显示出来。若不指定任何文件名称,或是所给予的文件名为 -,则 grep 指令会从标准输入设备读取数据。
1 | 语法结构 |
- pattern - 表示要查找的字符串或正则表达式。
- files - 表示要查找的文件名,可以同时查找多个文件,如果省略 files 参数,则默认从标准输入中读取数据。
常用选项
-i:忽略大小写进行匹配。-v:反向查找,只打印不匹配的行。-n:显示匹配行的行号。-r:递归查找子目录中的文件。-l:只打印匹配的文件名。-c:只打印匹配的行数。
参数说明
- -a 或 –text : 不要忽略二进制的数据。
- -A<显示行数> 或 –after-context=<显示行数> : 除了显示符合范本样式的那一列之外,并显示该行之后的内容。
- -b 或 –byte-offset : 在显示符合样式的那一行之前,标示出该行第一个字符的编号。
- -B<显示行数> 或 –before-context=<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前的内容。
- -c 或 –count : 计算符合样式的列数。
- -C<显示行数> 或 –context=<显示行数>或-<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前后的内容。
- -d <动作> 或 –directories=<动作> : 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
- -e<范本样式> 或 –regexp=<范本样式> : 指定字符串做为查找文件内容的样式。
- -E 或 –extended-regexp : 将样式为延伸的正则表达式来使用。
- -f<规则文件> 或 –file=<规则文件> : 指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。
- -F 或 –fixed-regexp : 将样式视为固定字符串的列表。
- -G 或 –basic-regexp : 将样式视为普通的表示法来使用。
- -h 或 –no-filename : 在显示符合样式的那一行之前,不标示该行所属的文件名称。
- -H 或 –with-filename : 在显示符合样式的那一行之前,表示该行所属的文件名称。
- -i 或 –ignore-case : 忽略字符大小写的差别。
- -l 或 –file-with-matches : 列出文件内容符合指定的样式的文件名称。
- -L 或 –files-without-match : 列出文件内容不符合指定的样式的文件名称。
- -n 或 –line-number : 在显示符合样式的那一行之前,标示出该行的列数编号。
- -o 或 –only-matching : 只显示匹配PATTERN 部分。
- -q 或 –quiet或–silent : 不显示任何信息。
- -r 或 –recursive : 此参数的效果和指定”-d recurse”参数相同。
- -s 或 –no-messages : 不显示错误信息。
- -v 或 –invert-match : 显示不包含匹配文本的所有行。
- -V 或 –version : 显示版本信息。
- -w 或 –word-regexp : 只显示全字符合的列。
- -x –line-regexp : 只显示全列符合的列。
- -y : 此参数的效果和指定”-i”参数相同。
实例
1 | 在文件 file.txt 中查找字符串 "hello",并打印匹配的行: |
ispell
ispell命令用于拼写检查程序。
ispell预设会使用/usr/lib/ispell/english.hash字典文件来检查文本文件。若在检查的文件中找到字典没有的词汇,ispell会建议使用的词汇,或是让你将新的词汇加入个人字典。
1 | 语法结构 |
参数说明
- -a 当其他程序输出送到ispell时,必须使用此参数。
- -A 读取到”&Include File&”字符串时,就去检查字符串后所指定文件的内容。
- -b 产生备份文件,文件名为.bak。
- -B 检查连字错误。
- -C 不检查连字错误。
- -d<字典文件> 指定字典文件。
- -l 从标准输入设备读取字符串,结束后显示拼错的词汇。
- -L<行数> 指定内文显示的行数。
- -m 自动考虑字尾的变化。
- -M 进入ispell后,在画面下方显示指令的按键。
- -n 检查的文件为noff或troff的格式。
- -N 进入ispell后,在画面下方不显示指令的按键。
- -p<字典文件> 指定个人字典文件。
- -P 不考虑字尾变化的情形。
- -S 不排序建议取代的词汇。
- -t 检查的文件为TeX或LaTeX的格式。
- -V 非ANSI标准的字符会以”M-^”的方式来显示。
- -w<非字母字符> 检查时,特别挑出含有指定的字符。
- -W<字符串长度> 不检查指定长度的词汇。
- -x 不要产生备份文件。
实例
1 | 检查文件的拼写。例如,检查testfile文件,可使用如下命令: |
其中,testfile.bak 文件就是刚才命令生成的备份文件,内容与原来的testfile 文件内容是一样的。
jed
jed命令用于编辑文本文件。Jed是以Slang所写成的程序,适合用来编辑程序原始代码。
1 | 语法结构 |
参数说明
- -2 显示上下两个编辑区。
- -batch 以批处理模式来执行。
- -f<函数> 执行Slang函数。
- -g<行数> 移到缓冲区中指定的行数。
- -i<文件> 将指定的文件载入缓冲区。
- -n 不要载入jed.rc配置文件。
- -s<字符串> 查找并移到指定的字符串。
实例
1 | jed主要用于编辑程序的源码,编辑源码时将以彩色高亮的方式显示程序的语法。例如使用jed编辑一个C语言的源代码文件,可使用如下命令: |
joe
joe命令用于编辑文本文件。Joe是一个功能强大的全屏幕文本编辑程序。操作的复杂度要比Pico高一点,但是功能较为齐全。Joe一次可开启多个文件,每个文件各放在一个编辑区内,并可在文件之间执行剪贴的动作。
1 | 语法结构 |
参数说明
以下为程序参数
-asis 字符码超过127的字符不做任何处理。
-backpath<目录> 指定备份文件的目录。
-beep 编辑时,若有错误即发出哗声。
- -columns<栏位> 设置栏数。
- -csmode 可执行连续查找模式。
- -dopadding 是程序跟tty间存在缓冲区。
- -exask 在程序中,执行”Ctrl+k+x”时,会先确认是否要保存文件。
- -force 强制在最后一行的结尾处加上换行符号。
- -help 执行程序时一并显示帮助。
- -keepup 在进入程序后,画面上方为状态列。
- -lightoff 选取的区块在执行完区块命令后,就会回复成原来的状态。
- -lines<行数> 设置行数。
- -marking 在选取区块时,反白区块会随着光标移动。
- -mid 当光标移出画面时,即自动卷页,使光标回到中央。
- -nobackups 不建立备份文件。
- -nonotice 程序执行时,不显示版权信息。
- -nosta 程序执行时,不显示状态列。
- -noxon 尝试取消”Ctrl+s”与”Ctrl+q”键的功能。
- -orphan 若同时开启一个以上的文件,则其他文件会置于独立的缓冲区,而不会另外开启编辑区。
- -pg<行数> 按”PageUp”或”PageDown”换页时,所要保留前一页的行数。
- -skiptop<行数> 不使用屏幕上方指定的行数。
- 以下为文件参数
- +<行数> 指定开启文件时,光标所在的行数。
- -autoindent 自动缩排。
- -crlf 在换行时,使用CR-LF字符。
- -indentc<缩排字符> 执行缩排时,实际插入的字符。
- -istep<缩排字符数> 每次执行缩排时,所移动的缩排字符数。
- -keymap<按键配置文件> 使用不同的按键配置文件。
- -linums 在每行前面加上行号。
- -lmargin<栏数> 设置左侧边界。
- -overwrite 设置覆盖模式。
- -rmargin<栏数> 设置右侧边界。
- -tab<栏数> 设置tab的宽度。
- -rdonly 以只读的方式开启文件-wordwrap编辑时若超过右侧边界,则自动换行。
实例
1 | 利用joe命令编辑文本文件。例如利用joe编辑C 语言源代码main.c,使用如下命令: |
joe编辑器有一些常用的组合键,例如可以通过Ctrl+K+H 寻求联机帮助,首先按Ctrl+K组合键,再输入字母H,即可调出帮助菜单,通过该帮助信息可以方便地获知如何对joe 编辑器进行操作。
join
join命令用于将两个文件中,指定栏位内容相同的行连接起来。找出两个文件中,指定栏位内容相同的行,并加以合并,再输出到标准输出设备。
1 | 语法结构 |
参数说明
- -a<1或2> 除了显示原来的输出内容之外,还显示指令文件中没有相同栏位的行。
- -e<字符串> 若[文件1]与[文件2]中找不到指定的栏位,则在输出中填入选项中的字符串。
- -i或–igore-case 比较栏位内容时,忽略大小写的差异。
- -o<格式> 按照指定的格式来显示结果。
- -t<字符> 使用栏位的分隔字符。
- -v<1或2> 跟-a相同,但是只显示文件中没有相同栏位的行。
- -1<栏位> 连接[文件1]指定的栏位。
- -2<栏位> 连接[文件2]指定的栏位。
- –help 显示帮助。
- –version 显示版本信息。
实例
1 | 为了清楚地了解join命令,首先通过cat命令显示文件testfile_1和 testfile_2 的内容。 |
look
ook命令用于查询单词。look指令用于英文单字的查询。您仅需给予它欲查询的字首字符串,它会显示所有开头字符串符合该条件的单字。
1 | 语法结构 |
参数说明
- -a 使用另一个字典文件web2,该文件也位于/usr/dict目录下。
- -d 只对比英文字母和数字,其余一慨忽略不予比对。
- -f 忽略字符大小写差别。
- -t<字尾字符串> 设置字尾字符串。
实例
1 | 为了查找在testfile文件中以字母L开头的所有的行,可以输入如下命令: |
mtype
mtype为mtools工具指令,模拟MS-DOS的type指令,可显示MS-DOS文件的内容。
1 | 语法结构 |
参数说明
- -s 去除8位字符码集的第一个位,使它兼容于7位的ASCII。
- -t 将MS-DOS文本文件中的”换行+光标移至行首”字符转换成Linux的换行字符。
实例
1 | 打开名为dos.txt 的MS-DOS文件可使用如下命令: |
pico
pico命令用于编辑文字文件。pico是个简单易用、以显示导向为主的文字编辑程序,它伴随着处理电子邮件和新闻组的程序pine而来。
1 | 语法结构 |
参数说明
- -b 开启置换的功能。
- -d 开启删除的功能。
- -e 使用完整的文件名称。
- -f 支持键盘上的F1、F2…等功能键。
- -g 显示光标。
- -h 在线帮助。
- -j 开启切换的功能。
- -k 预设pico在使用剪下命令时,会把光标所在的列的内容全部删除。
- -m 开启鼠标支持的功能,您可用鼠标点选命令列表。
- -n<间隔秒数> 设置多久检查一次新邮件。
- -o<工作目录> 设置工作目录。
- -q 忽略预设值。
- -r<编辑页宽> 设置编辑文件的页宽。
- -s<拼字检查器> 另外指定拼字检查器。
- -t 启动工具模式。
- -v 启动阅读模式,用户只能观看,无法编辑文件的内容。
- -w 关闭自动换行,通过这个参数可以编辑内容很长的列。
- -x 关闭换面下方的命令列表。
- -z 让pico可被Ctrl+z中断,暂存在后台作业里。
- +<列数编号> 执行pico指令进入编辑模式时,从指定的列数开始编辑。
实例
1 | 使用pico命令来编辑testfile文件,在终端中输入如下命令: |
rgrep
rgrep命令用于递归查找文件里符合条件的字符串。
rgrep指令的功能和grep指令类似,可查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设rgrep指令会把含有范本样式的那一列显示出来。
1 | 语法结构 |
参数说明
- -? 显示范本样式与范例的说明。
- -B 忽略二进制的数据。
- -c 计算符合范本样式的列数。
- -D 排错模式,只列出指令搜寻的目录清单,而不会读取文件内容。
- -F 当遇到符号连接时,rgrep预设是忽略不予处理,加上本参数后,rgrep指令就会读取该连接所指向的原始文件的内容。
- -h 特别将符合范本样式的字符串标示出来。
- -H 只列出符合范本样式的字符串,而非显示整列的内容。
- -i 忽略字符大小写的差别。
- -l 列出文件内容符合指定的范本样式的文件名称。
- -n 在显示符合坊本样式的那一列之前,标示出该列的列数编号。
- -N 不要递归处理。
- -r 递归处理,将指定目录下的所有文件及子目录一并处理。
- -R<范本样式> 此参数的效果和指定”-r”参数类似,但只主力符合范本样式文件名称的文件。
- -v 反转查找。
- -W<列长度> 限制符合范本样式的字符串所在列,必须拥有的字符数。
- -x<扩展名> 只处理符合指定扩展名的文件名称的文件。
- –help 在线帮助。
- –version 显示版本信息。
实例
1 | 在当前目录下查找句子中包含"Hello"字符串的文件,可使用如下命令: |
sed
sed 命令是利用脚本来处理文本文件。sed 可依照脚本的指令来处理、编辑文本文件。
Sed 主要用来自动编辑一个或多个文件、简化对文件的反复操作、编写转换程序等。
1 | 语法结构 |
参数说明
- -e